前言
本文翻译并总结归纳自 Hands-On Machine Learning for Cybersecurity 书中的 Chapter 1: Basics of Machine Learning in Cybersecurity。该书主要着眼于机器学习在网络安全领域中的应用,介绍了多个方向的原理和解决方案,比如:包时间序列分析、垃圾邮件检测、使用 k-means 算法的网络异常检测等。总的来说,该书的动手操作很多,实战性很强。接下来我会用一个系列,整理归纳书中的各个章节。当然,除了第一章是介绍机器学习的概览之外,其他几个章节内容比较离散,所以顺序可能打乱。
背景
自诞生以来,机器学习(Machine Learning)一直是一个非常热门的话题,它的出现实实在在地解决了很多问题,比如人脸识别、自动驾驶、购物推荐系统、聊天机器人等。
而在安全领域方面,老式的威胁检测系统通过使用启发式的和静态的签名(signature)来检测威胁和异常。例如:杀毒软件会根据病毒程序的特征,生成并维持一个病毒的签名库(保持持续更新),在查杀时通过与库中的签名比对来识别病毒程序。基于签名的威胁检测技术虽然容易理解,但并不健壮,它的最大的问题之一是:在数据规模、数据流速显著增大时,如何保证签名比对过程与数据流入速度匹配。每个包需要与数据库中的每个签名比对,如果不能保持同步,那意味着只能抛弃部分数据包,由此就会产生“漏网之鱼”。
如今,基于签名的系统逐渐被智能网络安全代理(Intelligent cybersecurity agent)所取代。机器学习在识别新型恶意软件、零日漏洞攻击(zero-day attack)、高级可持续威胁(advanced persistent threats,简称 APT)方面取得积极进展。
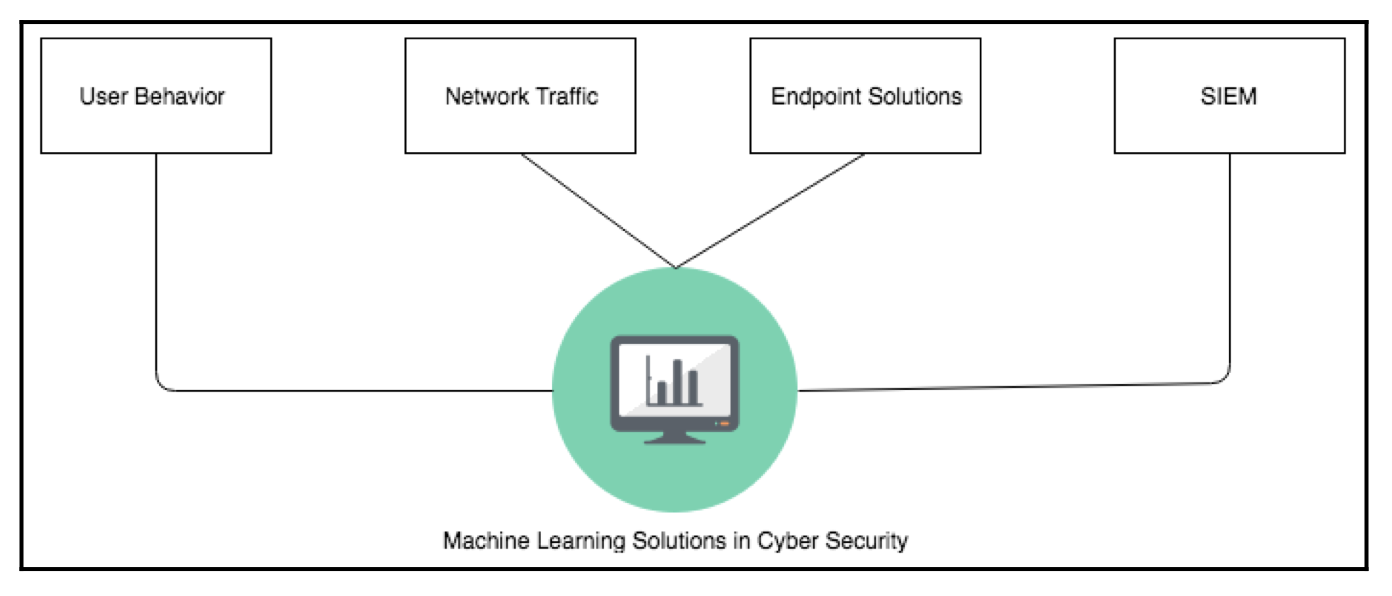
一般来说,由于攻击的复杂特性,要做到完全预防是很难的,机器学习能做到在攻击的初期识别攻击并防止其扩散到整个系统。许多网络安全公司使用诸如用户行为分析(user behavior analytics)和预测分析(predictive analytics)的高级分析方法,在威胁生命周期的早期阶段识别 APT 攻击,这种方式能够有效预防身份数据泄漏和内部威胁。规范分析(prescriptive analytics)则更具有响应性,能够在网络攻击发生以后分析该采取什么响应措施能将损失降到最小。
机器学习中的数据
数据是机器学习的核心。数据分为结构化数据和非结构化数据,结构化数据(structured data)可以被映射为二维表结构,包含表头(Header)和表内元素,传统的关系型数据库(RDBMS)如 MySQL、Oracle 等都是以这种方式存放结构化数据;而非结构化数据(unstructured data)数据结构不规则或不完整,没有预定义的数据模型,例如图片、音频/视频等;融合了结构化和非结构化的数据称为半结构化数据(semi-structured data)。
根据数据是否被打上标记,数据又被分为有标注数据(labelled data)和无标注数据(unlabelled data)。例如网络安全中的恶意流量检测,可以将样本中的善意流量(white)和恶意流量(black)手动打标(恶意流量可能是自己模拟生成的),构成训练集训练机器学习模型。
机器学习阶段
机器学习分为以下四个阶段:
- 分析阶段(The analysis phase):在这个阶段,采集到的数据需要被提取明确的特征(features)或者参数(parameters),来被用于训练模型。
- 训练阶段(The training phase): 前一阶段的数据将被用来在这个阶段训练机器学习模型(machine learning model),训练阶段是一个多次迭代的阶段,目的是为了训练一个更加可信的模型。
- 测试阶段(The testing phase): 在这一阶段,训练阶段产生的机器学习模型将结合更多的数据进行测试并评估模型的性能。测试的数据是前面阶段从未被使用的数据。模型的演化可能会需要参数训练(调参)。
- 应用阶段(The application phase) :模型被部署到生产环境,应用于真实数据。
过拟合和欠拟合
在训练阶段,由于样本数据的不完备,训练出的机器学习模型可能并不理想(模型的泛化能力不佳),会产生两种现象:过拟合和欠拟合。
过拟合(Overfitting),是指系统太过适应于(fit)或者说太过依赖于训练集数据,导致新来的数据都视为不匹配,通常表现为:模型对于训练集表现很好,对于测试集表现很差(容纳度很低)。产生这种现象的常见原因之一是只使用了有标注的数据来训练模型。
Overfitting: The production of an analysis that corresponds too closely or exactly to a particular set of data, and may therefore fail to fit additional data or predict future observations reliably. – Oxford Dictionary
欠拟合(Underfitting),是模型表现差的另一种场景,通常是由于样本数量较少,模型训练依赖特征过少,学习能力低下造成的。
对于这两种情形,可以通过一些机器学习的常见步骤来消除,比如:数据的交叉验证(cross validation of the data),数据修剪(data pruning)和数据正则化(regularization of the data)。
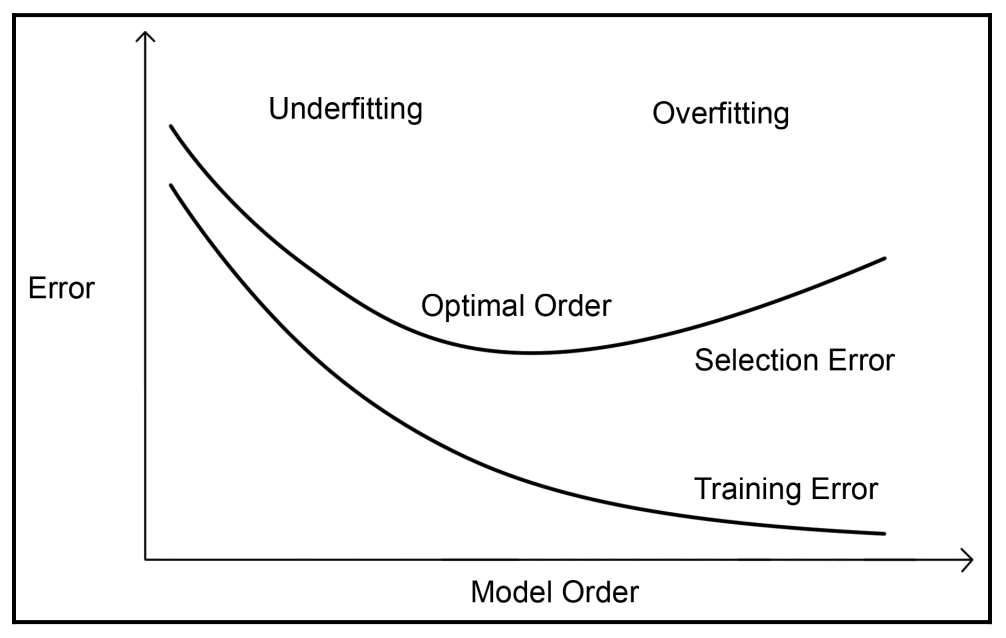
由上图可以看到,当模型层级较低时(模型过于简单),表现为欠拟合,训练集和测试集效果都不好;当模型层级较高时(模型过于复杂),表现为过拟合,训练集效果很好,但由于学习能力过于强大,以至于把训练样本所包含的不太一般的特性都学到了,导致测试集中表现很差。所以我们需要摸索出合适的模型,既不能太简单也不能太复杂,使得在测试集上能有最优表现。
机器学习分类
传统上,基于所提供的学习类型,机器学习系统大体上可以分为两类:有监督学习和无监督学习。强化学习和深度学习是后面引入的新的研究分支。

有监督学习
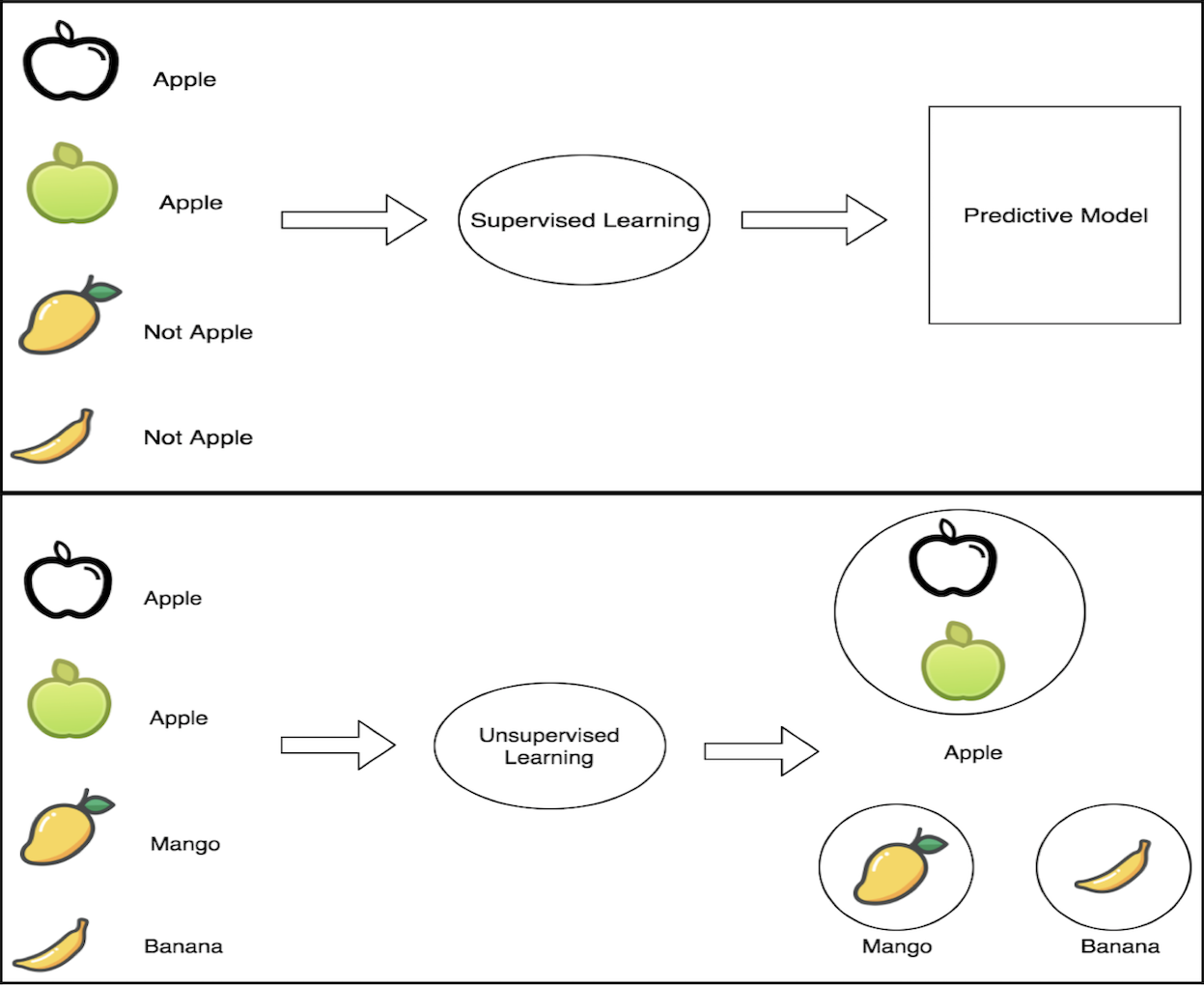
有监督学习(Supervised learning)是指使用已标注的数据集推导出预测函数,对测试集进行分类和预测。有监督学习包含一些子分支,比如:
- 半监督学习(Semi-supervised learning):训练阶段的数据集即含有有标注的,也含有未标注的。
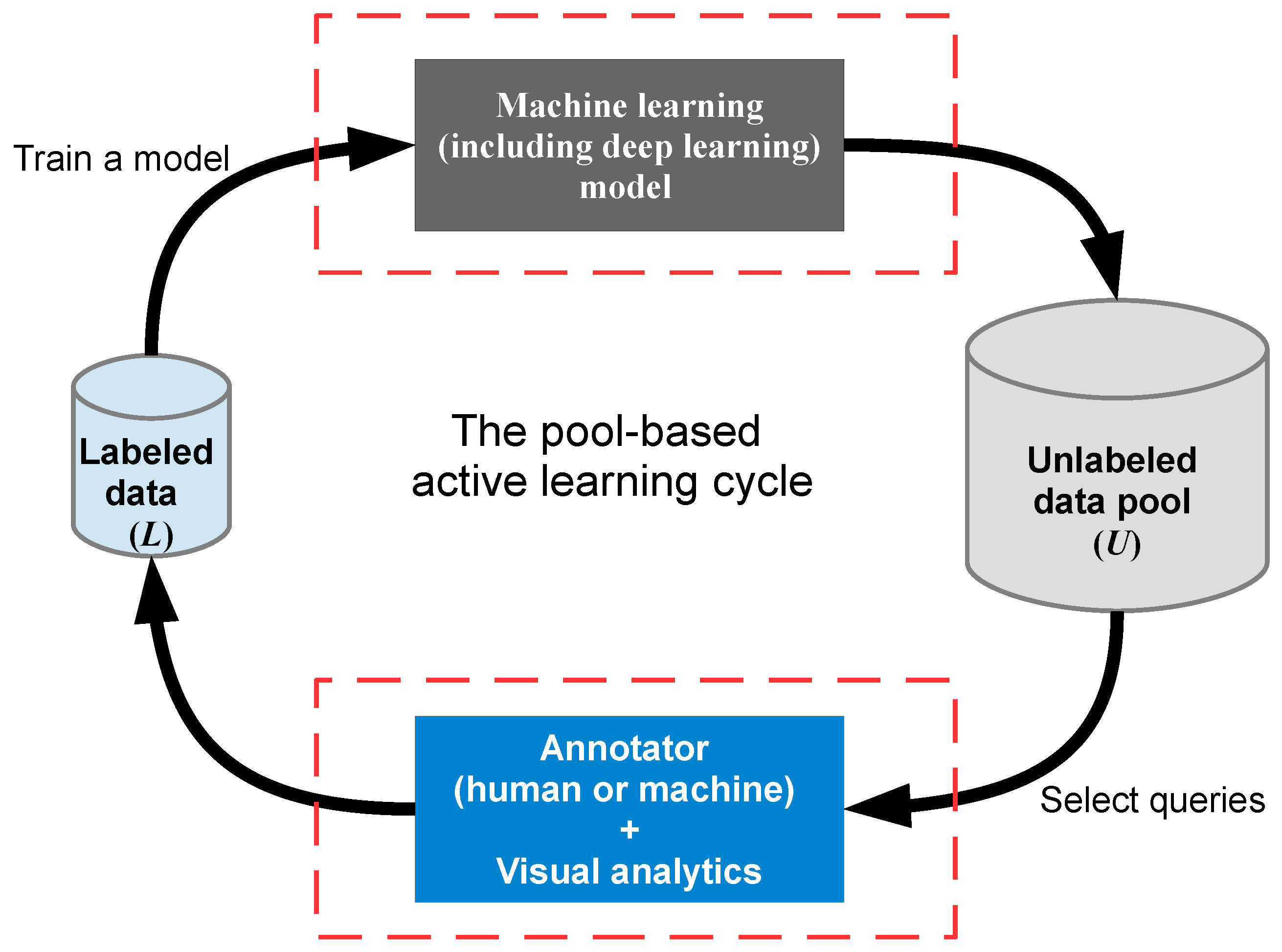
- 主动学习(Active learning):主动学习是指,通过查询函数,从未标注数据集中查询出信息熵最大(可以简单理解为最复杂)的数据,交给督导者进行标注,循环迭代这个过程直至模型达到最佳。主动学习的“主动”,指的是主动提出标注请求,为此需要一个外在的能够对其请求进行标注的实体(通常是相关领域人员)。
![e834d2167c02ba1908f13760cec58005.png]()
有监督学习的常见应用包括:人脸识别,需要人为标注新面孔;垃圾邮件检测,需要对邮件内容文本进行分词处理,所以需要提前对一些敏感词汇做人为标注。
无监督学习
无监督学习算法(Unsupervised learning)是指初始数据集是未标注的,数据视图是在处理过程中由系统自学习构建出来的,没有任何外部干涉。如果说有监督学习是:老师提供对错指示,要求学生能够“对于输入数据X能判断对错”,那么无监督学习就是:在没有老师的情况下,学生自学,要求学生能够“从数据X中归纳总结出知识点”。无监督学习算法的具体应用案例包括:用户行为分析(User behavior analysis)、购物篮分析(Market basket analysis)等。
强化学习
强化学习(Reinforcement learning)是机器学习的又一分支,它强调如何基于环境而行动,以取得最大化的预期利益。
具有强化学习能力的程序或机器人被称为代理(Agent)。代理所解决的问题被抽象为环境(Environment),比如迷宫或者棋盘。代理需要有一个基本的策略(Policy),每次迭代根据这个策略选择一个动作(Action)作用于环境,环境接受该动作后状态(State)发生变化,同时产生一个信号(Reward),正代表奖励,负代表惩罚。代理会根据这个信号评估之前的策略是否适合。
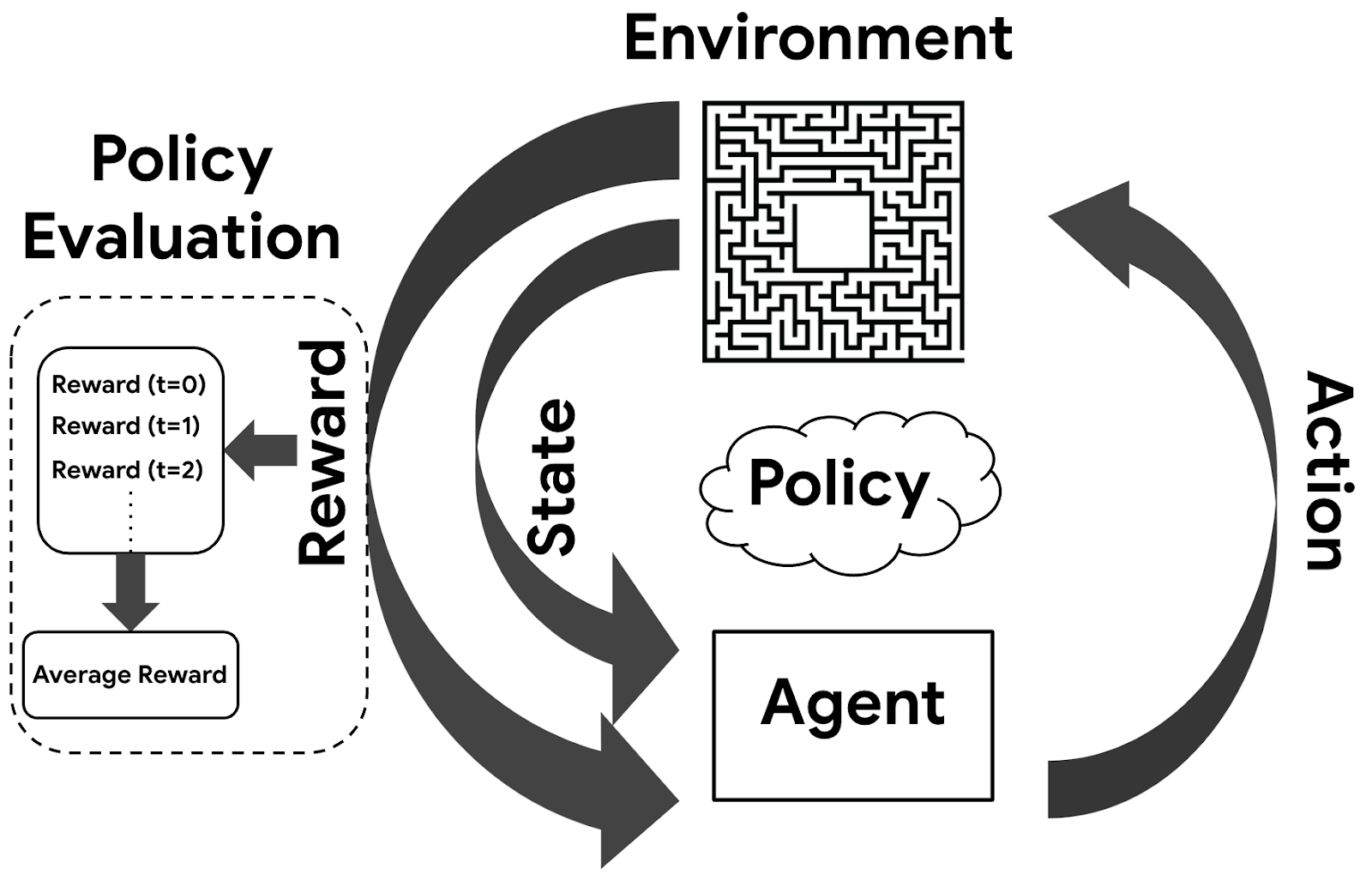
强化学习有一些实际的用例,比如自动驾驶汽车,需要对周围复杂环境作出实施迅速的应对;又比如家喻户晓的 AlphaGo,只需要训练4个小时就可以击败世界知名的象棋AI Stockfish。
深度学习
深度学习(Deep learning)是机器学习领域的一个新的研究分支,是一种以人工神经网络为架构,对资料进行表征学习的算法。深度学习并不简单的囊括于传统的有监督/无监督分类中,它本身也会用到有监督和无监督的学习方法来训练深度神经网络。
深度学习的出现,引领了机器学习的又一波热潮,它摧枯拉朽地解决了之前未解决的诸多问题,使得似乎所有的机器辅助功能都变为可能。但它作为目前最热的机器学习方法之一,并不意味着是机器学习的终点,它也具有诸多问题,比如:深度学习需要巨大的数据集做支撑;复杂度较高;深度学习的构想来源于人脑的神经元结构,但人脑的复杂程度要远远超出它所能模拟的范畴。
机器学习解决的问题
机器学习可以用于解决以下几类问题:分类问题,集群问题,回归问题,降维问题,密度估算问题等等。
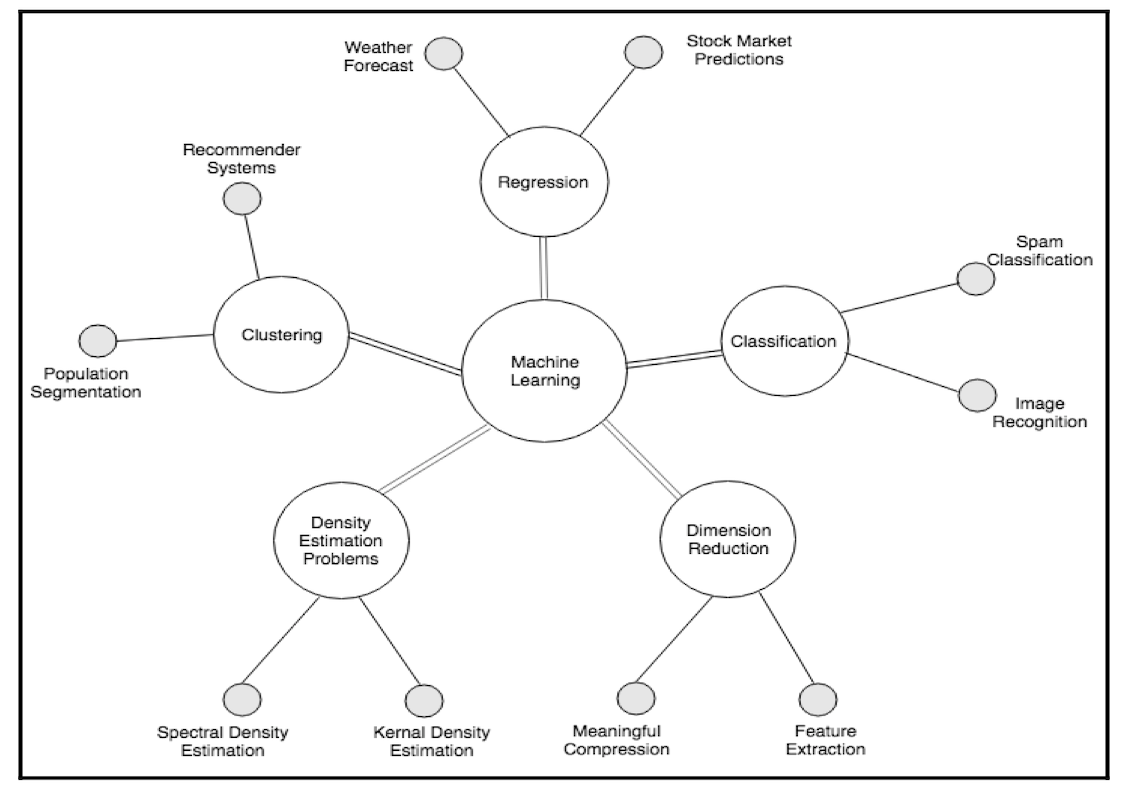
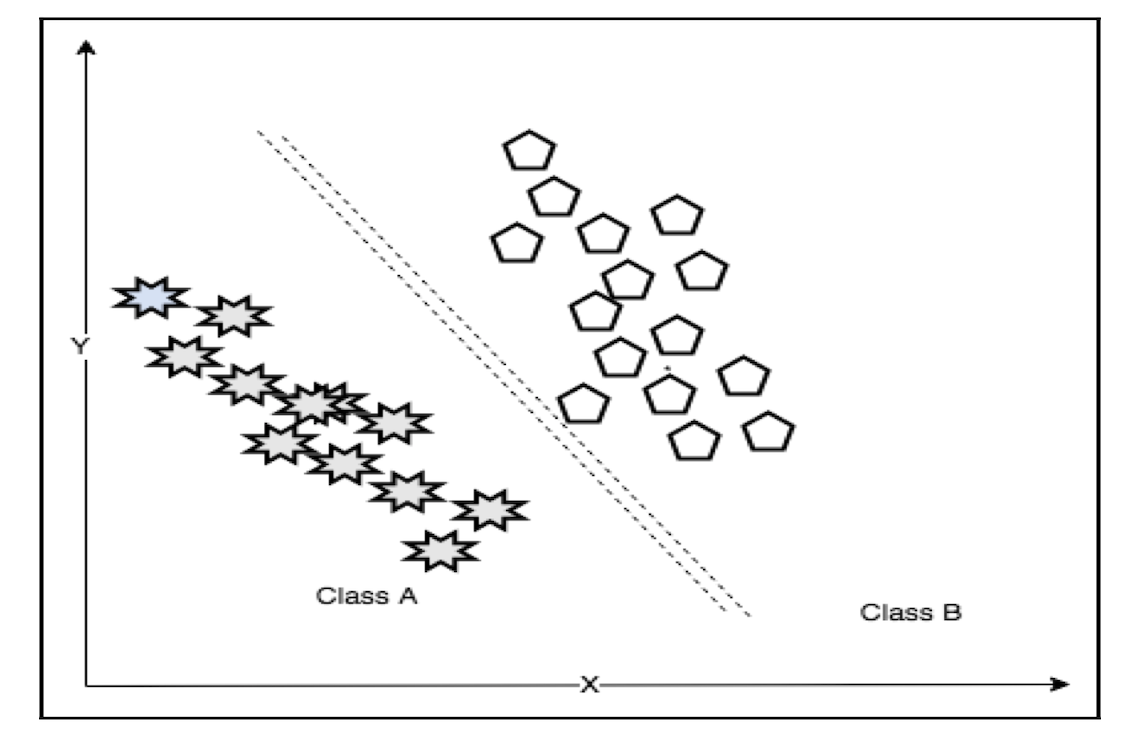
分类问题
分类问题(Classification problems)是指基于特征将数据划分到多个类(class)中的问题。因为训练数据是有标注的,所以分类问题属于有监督学习。网络数据分类是一个经典的分类问题,互联网的内容可以根据它们的文本内容比如新闻、社交媒体、广告等划分到它们对应的类别。
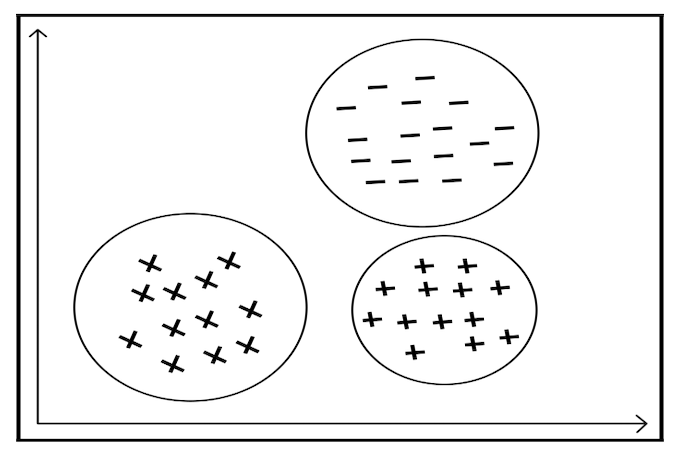
聚类问题
聚类问题(Clustering problems)是指将数据分成若干组并将相似数据归为一组。聚类技术常用语信息检索、模式识别、人口统计分析领域。相比于分类问题,聚类问题并不关心某一类是什么,只需要将相似的数据归为一类。因此,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了,也就是说训练集无需作出预先标注。
回归问题
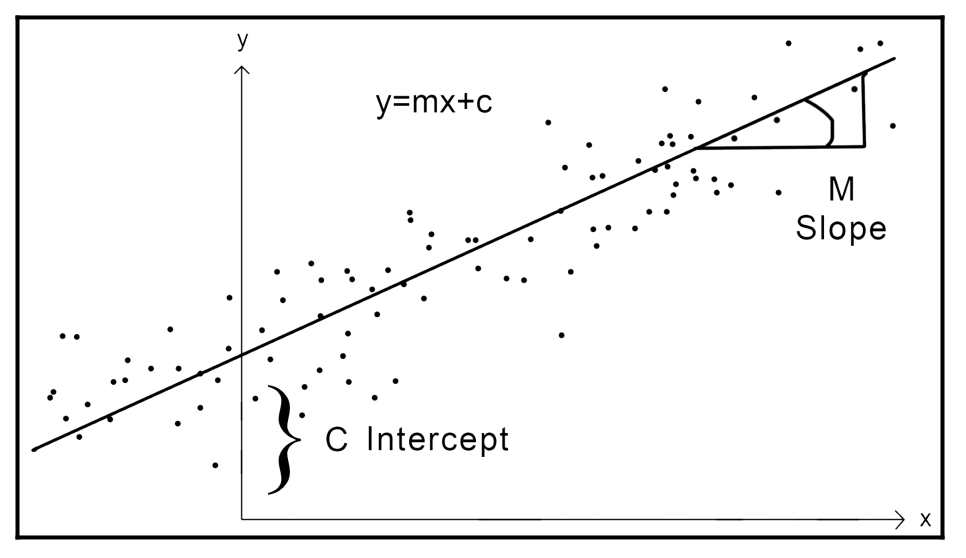
回归问题(Regression problems)指的是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。例如对于图中的二元组数据(x,y),我们可以求出能表示 x,y 关系的线性回归方程,再对接下来的测试数据集进行预测或分类。
回归包括多种类型,比如:线性回归(linear regression),逻辑回归(logistic regression),多项式回归(polynomial regression)等。回归可以用于欺诈检测系统,股票市场分析和预测。
降维问题
现实应用中属性维数经常成千上万,且许多学习方法都涉及距离计算,而高维空间会给距离计算带来很大的麻烦,当维数很高时甚至连计算内积都不再容易。事实上,在高维情形下出现的数据样本稀疏、距离计算困难等问题,是所有机器学习方法共同面临的严重障碍,被称为“维数灾难”(curse of dimensionality)。
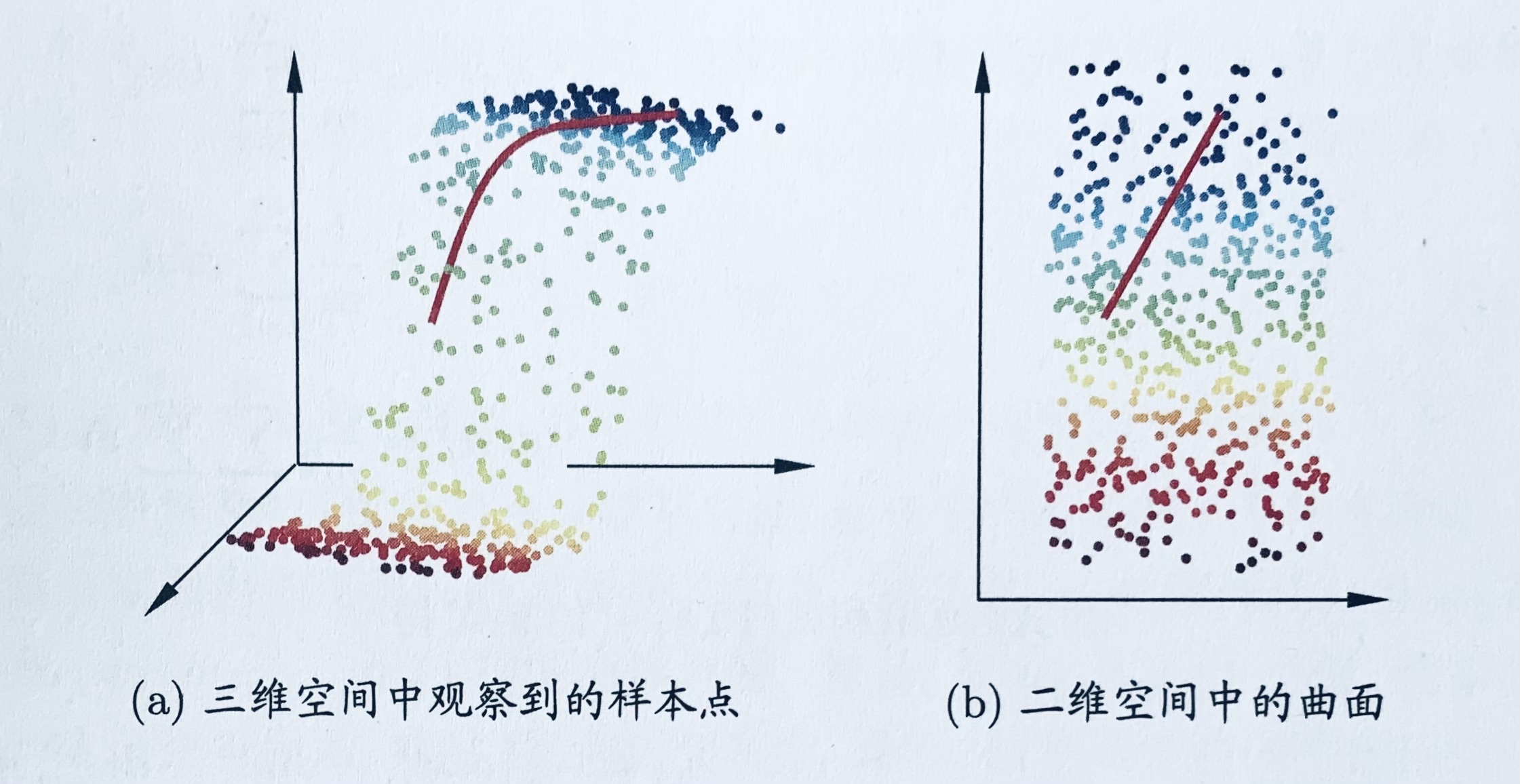
缓解维数灾难的一个重要途径是降维(Dimension reduction),亦称“维数约简”,即通过某种数学变换将原始高维属性空间转变为一个低维“子空间”(subspace),在这个子空间中样本密度大幅提高,距离计算也变得更为容易。降维将含有多个属性的高维数据,用它的主要属性去表示,并且不丢失重要特征。 降维技术经常用于特征提取,比如网络包流数据的处理,为了减少数据规模,通常只提取具有代表性的有用特征进行分析。
下图给出了一个直观的例子,将原始三维空间中的样本点,映射到二维嵌入子空间中。
密度估算问题
密度估算问题(Density estimation problems)是用于对密集数据进行机器学习估算的统计学习方法。从技术上讲,它是一种计算概率密度函数的技术。在医学分析领域,通常使用这种技术来在庞大的人口中识别疾病相关症状。
机器学习算法
SVM
支持向量机(Support Vector Machines,SVM)属于有监督的算法,被用于解决线性或非线性的分类问题(linear/non linear classification)。由于优秀的性能,SVM 得到了广泛的应用。
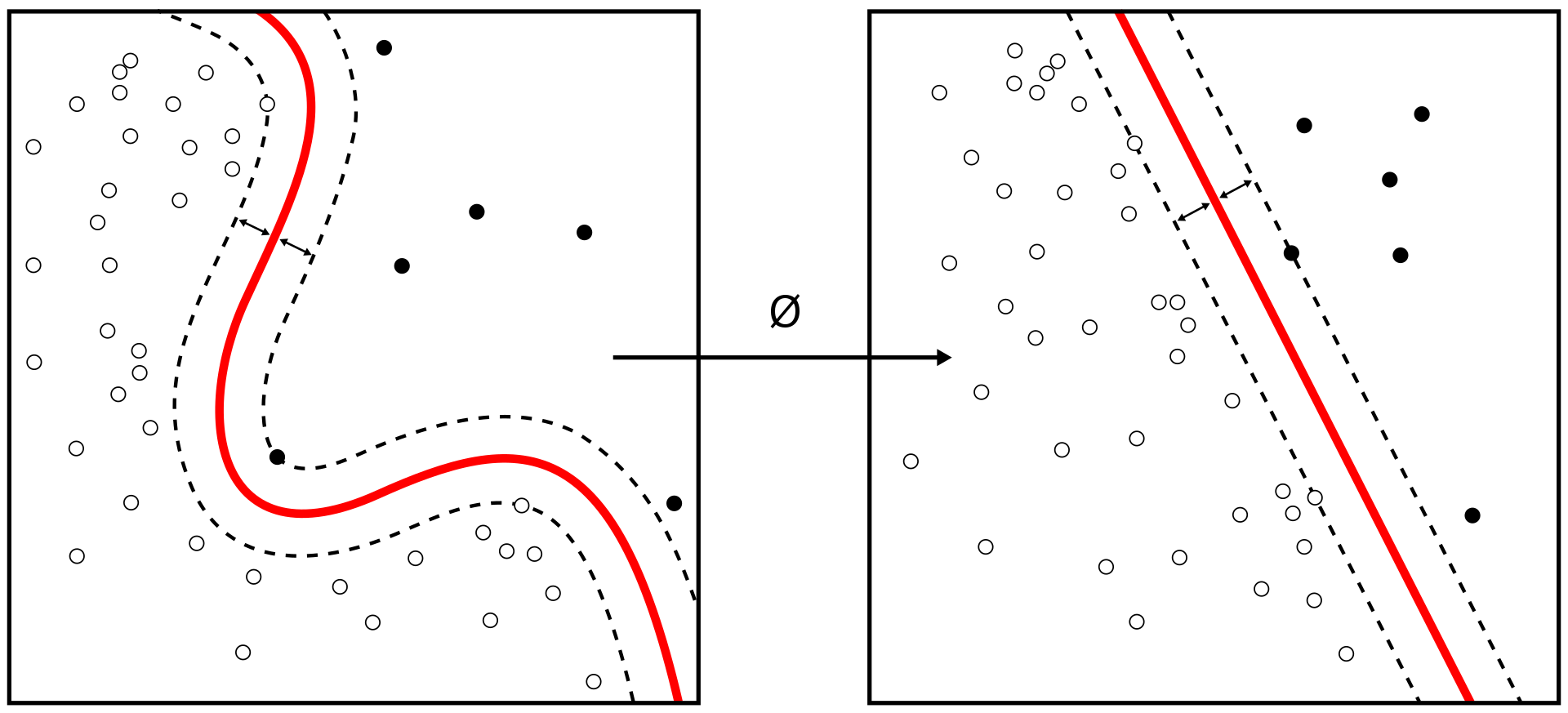
若输入数据所在的特征空间存在作为决策边界(decision boundary)的超平面将样本按正类和负类分开,实际上构造了2个平行的超平面作为间隔边界以判别样本的分类,所有在上间隔边界上方的样本属于正类,在下间隔边界下方的样本属于负类。两个间隔边界的距离被定义为边距(margin),位于间隔边界上的正类和负类样本为支持向量(support vector)。SVM 旨在求解能够划分样本的最大边距超平面(maximum-margin hyperplane)。
对于二维平面,超平面可以理解为可以划分样本的一条「直线」,对于高维特征空间,SVM 可以通过核方法(kernel method)进行非线性分类。
贝叶斯网络
贝叶斯网(Bayesian network,简称 BN)亦称“信念网”(belief network),它借助有向无环图(Direct Acyclic Graph,简称 DAG)来刻画属性之间的依赖关系,并使条件概率表(Conditional Probability Table,简称 CPT)来描述属性的联合概率分布。
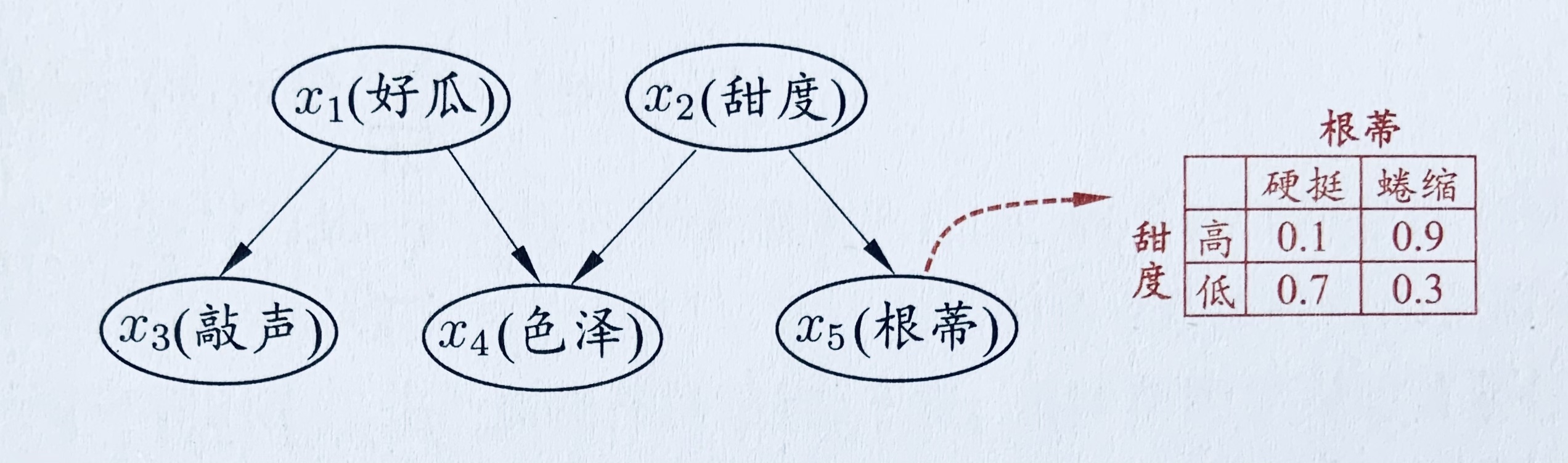
上图给出了西瓜问题的一种贝叶斯网结构和属性“根蒂”的条件概率表。从图中网络结构可看出,“色泽”直接依赖于“好瓜”和“甜度”,而“根蒂”则直接依赖于“甜度”;进一步从条件概率表能得到“根蒂”对“甜度”量化依赖关系,如 $P(根蒂=硬挺|甜度=高)=0.1$ 等。
决策树
决策树(decision tree)是一类常见的机器学习方法。以二分类任务为例,我们希望从给定训练数据集学得一个模型用以对新示例进行分类,这个把样本分类的任务,可看作对“当前样本属于正类吗?“这个问题的“决策”或“判定”过程。
顾名思义,决策树是基于树结构来进行决策的,这恰是人类在面临决策问题时一种很自然的处理机制。树中非叶子节点表示需要作出分类判断的属性,每个分支代表可能的属性值。下图给出了西瓜问题的一颗决策树。
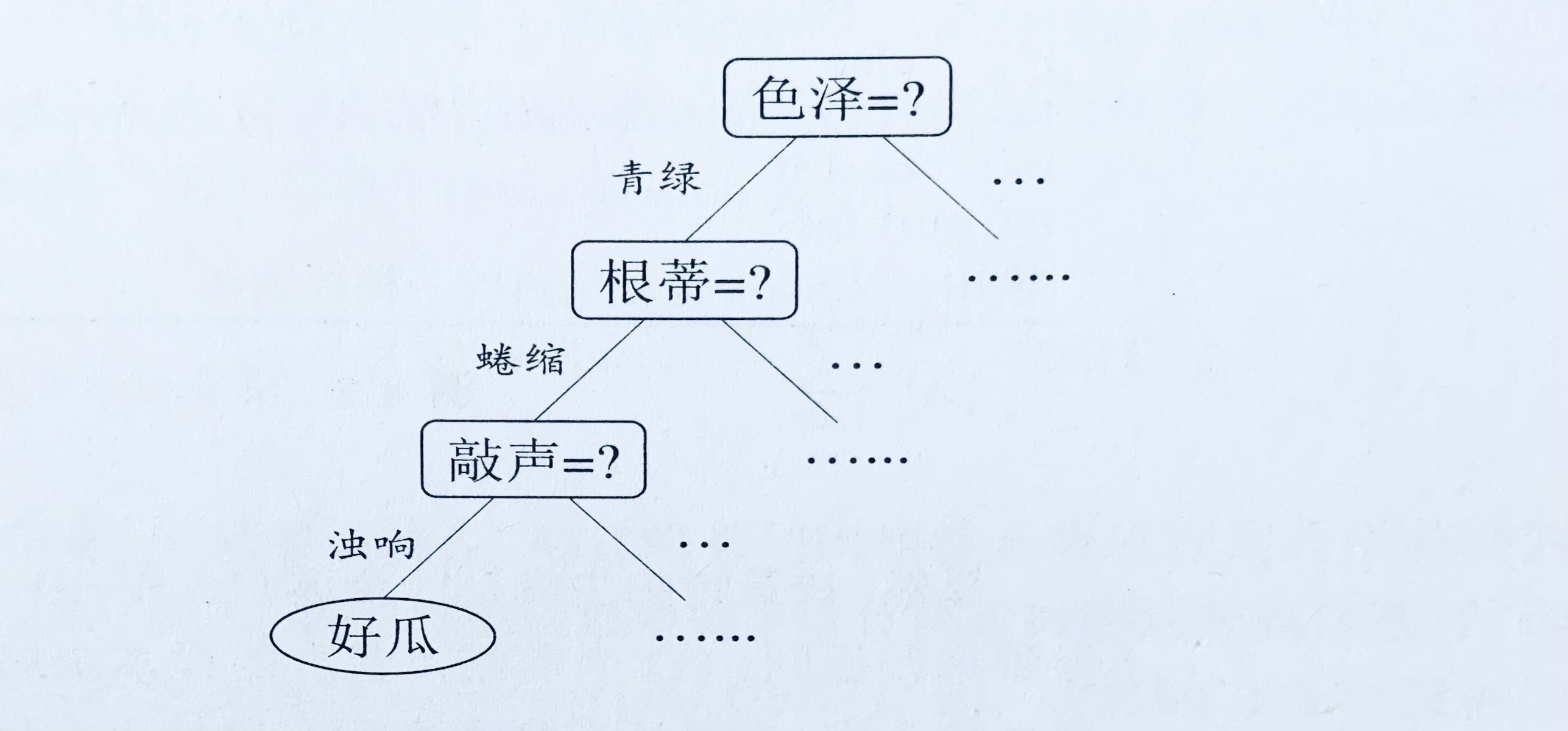
随机森林
首先我们介绍一下 Bagging。给定包含 m 个样本的数据集,我们先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中,这样,经过m次随机采样操作,我们得到含 m 个样本的采样集,初始训练集中有的样本在采样集里多次出现,有的则从未出现。
照这样,我们可采样出 T 个含 m 个训练样本的采样集,然后基于每个采样集训练出一个基学习器,再将这些基学习器进行结合。这就是 Bagging 的基本流程。在对预测输出进行结合时,Bagging 通常对分类任务使用简单投票法,对回归任务使用简单平均法。若分类预测时出现两个类收到同样票数的情形,则最简单的做法是随机选择一个,也可进一步考察学习器投票的置信度来确定最终胜者。
随机森林(Random Forest,简称 RF)是 Bagging 的一个扩展变体。RF 在以决策树为基学习器构建 Bagging 集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。具体来说,传统决策树在选择划分属性时是在当前结点的属性集合(假定有 d 个属性)中选择一个最优属性;而在 RF 中,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包含 k 个属性的子集,然后再从这个子集中选择一个最优属性用于划分。这样使得随机森林中的决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。
随机森林简单、容易实现、计算开销小,令人惊奇的是,它在很多现实任务中展现出强大的性能,被誉为“代表集成学习技术水平的方法”。
kNN
k近邻(k-Nearest Neighbor,简称 kNN)学习是一种常用的监督学习方法,其工作机制非常简单:给定测试样本,基于某种距离度量找出训练集中与其最靠近的 k 个训练样本,然后基于这 k 个“邻居”的信息来进行预测。通常,在分类任务中可使用“投票法”,即选择这 k 个样本中出现最多的类别标记作为预测结果;在回归任务中可使用“平均法,即将这 k 个样本的实值输出标记的平均值作为预测结果;还可基于距离远近进行加权平均或加权投票,距离越近的样本权重越大。
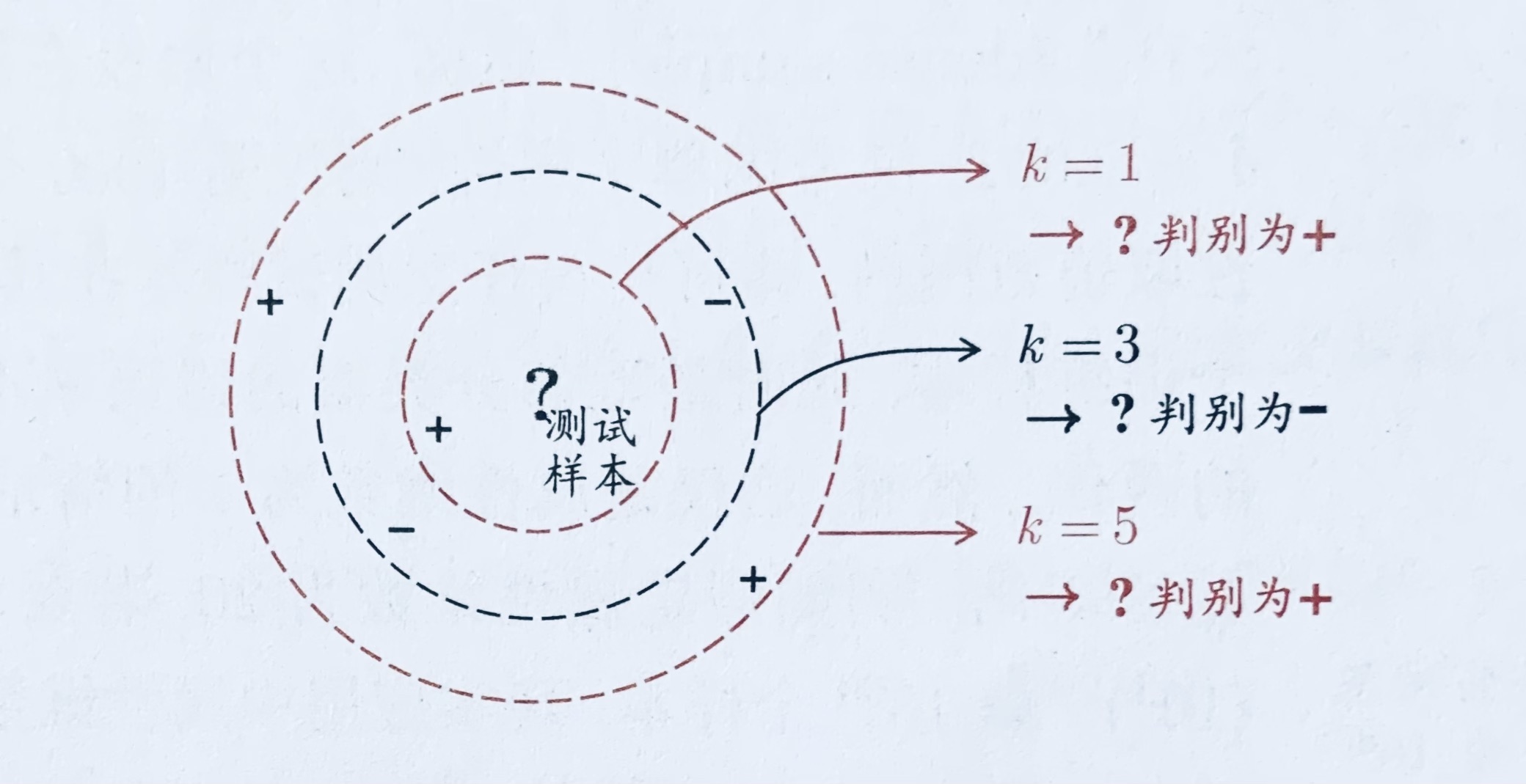
上图是一个k近邻分类器示意图。虚线为等距线,测试样本在 k=1 或 k=5 时被判别为正例,k=3 时被判别为反例。显然,k 是一个重要参数,当 k 取不同值时,分类结果会有显著不同。
神经网络
神经网络是由具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所作出的交互反应。
神经网络中最基本的成分是神经元(neuron)模型,即上述定义中的“简单单元”。在生物神经网络中,每个神经元与其他神经元相连,当它“兴奋”时,就会向相连的神经元发送化学物质,从而改变这些神经元内的电位;如果某神经元的电位超过一个“阈值”(threshold),那么它就会被激活,即“兴奋”起来,向其他神经元发送化学物质。
1943年,McMulloch 和 Pitts 将上述情形抽象为下图所示的简单模型,这就是一直沿用至今的“M-P神经元模型”。把许多个这样的神经元按一定的层次结构连接起来,就得到了神经网络。
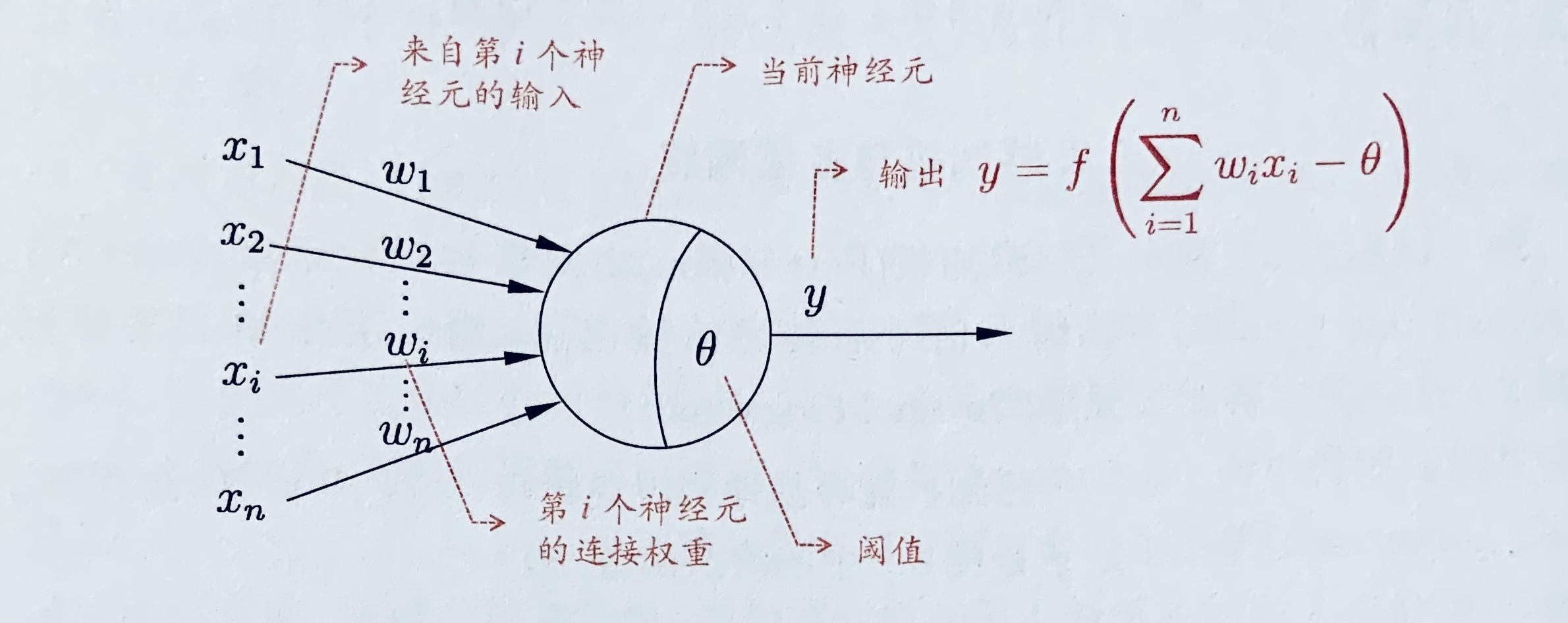
在这个模型中,神经元接收到来自 n 个其他神经元传递过来的输入信号,这些输入信号通过带权重的连接(connection)进行传递,神经元接收到总输入将与神经元的阈值进行比较,然后通过“激活函数”(activation function)处理以产生神经元的输出。
机器学习架构
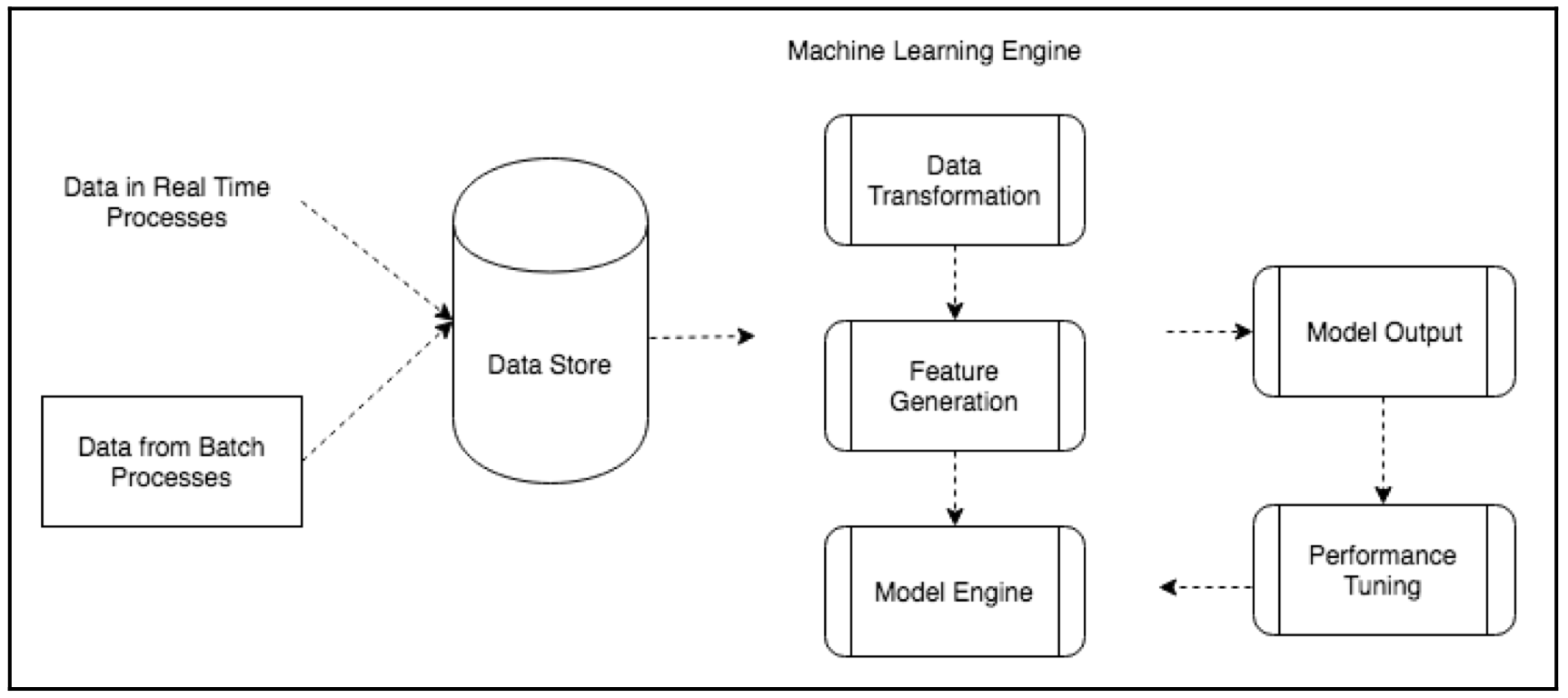
注入机器学习系统的数据可能来自不同的源,可以是实时的流数据,也可以是批处理数据或者无交互的定时任务数据。常见的数据源有 Amazon Kinesis、Apache Flume、Apache Kafka 等。注入的数据经过清洗和预处理后被存入数据储存库中,例如 SQL/NoSQL 数据库、数据仓库(data warehouse)、HDFS 分布式系统等等。
模型引擎
- 数据准备(Data preparation):数据准备阶段需要进行数据清洗(data cleansing),检查数据一致性和完整性,对数据进行规范化,对拆分的或是聚合的数据进行转换和重组。
- 特征生成(Feature generation):找到待分析数据的关键特征。特征可以来自原始数据或者聚合后的数据,不同特征通常都是相互独立的。特征提取的首要目标是降低数据维度和提高模型性能。
- 模型训练(Model training):机器学习模型分析数据间的关联,将数据分类到不同的组。为了获得最佳性能,需要对数据特征进行合适的采样。通常 70~80% 的数据会被用于训练阶段。
- 模型测试(Model testing):在测试阶段我们验证模型,模型的性能能够被测试并做出调节。交叉验证能够确定模型的性能。通常 20% 的数据会被用于测试阶段。
性能评估
性能调节(Performance tuning)和错误检测(error detection)是机器学习系统最重要的迭代过程,能够帮助提升系统的性能。如果系统的泛化功能能够以较高的概率给出较低的泛化误差(generalization error),我们称这个系统拥有最优性能。事实上这属于 PAC 理论的范畴。
泛化误差与分类的准确度,回归模型预测的精确度直接相关。为了计算泛化误差,我们给出一些评估指标:
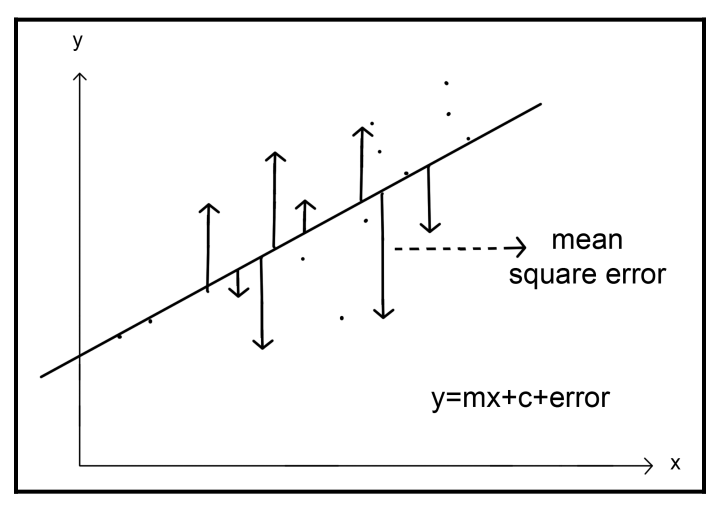
均方误差
假设现在有一条回归曲线,我们想测量每个点到回归线的距离,而均方误差(Mean squared error,MSE)就能够统计这些偏移量。$P_i$ 为预测值,$A_i$ 为真实值,MSE 对每个点偏移量的平方和求平均:
$$ MSE = \frac{1}{n}\sum_{i=1}^n{(P_i - A_i)^2} $$
平均绝对误差
平均绝对误差(Mean absolute error,MAE) 计算每个点绝对误差的均值。MAE 是时间序列分析中的预测误差的一个常见指标。相比于 MSE,由于 MSE 使用了平方会放大误差,所以 MSE 对于异常数据更加敏感,而 MAE 对异常点有更好的鲁棒性(抗干扰能力更强),更适合用来做预测分析。但对于学习效率来说,误差较大时 MSE 收敛更快精度更高。
$$ MAE = \frac{1}{n}\sum_{i=1}^n{|P_i - A_i|} $$
精确率、召回率、准确率
精确率、召回率和准确率是机器学习分类问题(classification problem)模型评估中常见的性能度量指标:
- 精确率(Precision),又叫查准率,定义为:$Precision \triangleq \frac{TP}{TP+FP}$
- 召回率(Recall),又叫查全率,定义为:$Recall \triangleq \frac{TP}{TP+FN}$
- 准确率(Accuracy),定义为:$Accuracy \triangleq \frac{TP+TN}{TP+TN+FP+FN}$
上述定义式中 T 代表 True,F 代表 False,T/F 表示预测是否正确;P 代表 Positive,N 代表 Negative,P/N 代表本身是正例还是反例。例如:恶意流量检测系统中,P 代表是恶意流量,那么 TP 就代表正确检测出恶意流量,FN 代表本身不是恶意流量却被错误地识别为恶意流量。
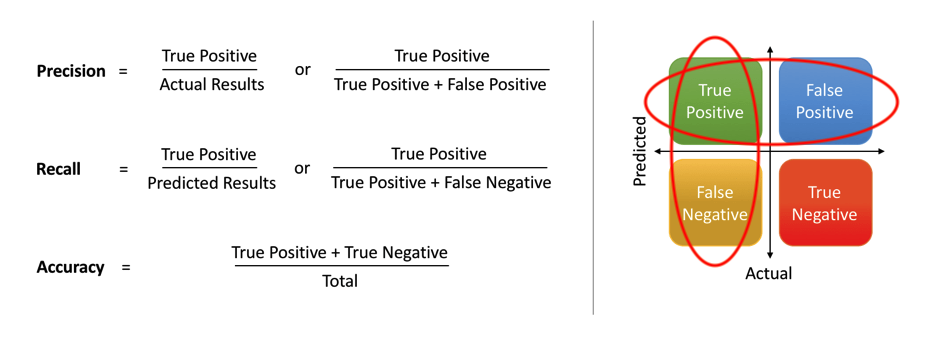
Precision 从预测结果角度出发,描述了预测出来的正例结果中有多少是真实正例,关心的是查出来的准不准;Recall 从真实结果角度出发,描述了测试集中的真实正例有多少被检测出来,关心的是查的全不全。Accuracy 则代表所有预测中正确预测所占的比例。
当正负样本分布严重不均匀时,仅仅靠准确率 Accuracy 去评估模型性能是不合适的。就拿恶意流量检测来说,假设恶意流量占总流量的 0.1%,那么考虑一个全部流量都 pass 的检测系统,它的准确率依然能达到 99.9%,但是一条恶意流量都没有检测出来,这显然是不合要求的。所以通常需要结合这三个指标对模型进行整体评估。
性能改善
那么如何提高模型的性能呢?通常可以通过:
- 改善数据质量:数据需要清洗、重采样以及规范化,特征提取步骤也可能需要重新审视,缺乏独立性的特征也会导致性能不佳。
- 更换算法:模型的性能不佳也可能是因为没有选对合适的算法,在这种情况下,不同算法的基准测试可以帮助我们做出合适的选择。基准测试包括但不限于:K倍交叉验证。
- **使用集成学习(Ensemble Learning)**:同时使用多种学习算法来获得比单独使用任何学习算法具有更好的性能。一些最复杂的人工智能系统就是这类集成的副产物。
机器学习扩展库
Python 作为机器学习最常用语言,虽然不是最快的,但因为它的灵活性而被数据科学家们广泛接受。Python 为机器学习专家提供了一系列的工具和扩展库,常用到的有:
- NumPy:是统计分析和机器学习方面的重要扩展库,提供了支持线性代数、傅立叶变换和其他数值分析的复杂函数库。
- SciPy:基于 NumPy 的科学计算库,可以处理插值、积分、优化、图像处理、常微分方程数值解的求解、信号处理等问题。
- Scikit-learn:简单高效的机器学习库,提供了解决分类、集群、回归等问题的机器学习算法模型,Scikit-learn 依赖于 NumPy 和 SciPy。
- pandas:非常强力的数据统计分析工具。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。能够很好的读写和呈现表格数据。
- Matplotlib:绘图工具,常常与 NumPy、SciPy 配合使用。
下图是 Scikit-learn 在解决不同规模,不同类型问题时推荐使用的算法模型:

参考
- Halder, S. & Ozdemir, S. Hands-On Machine Learning for Cybersecurity: Safeguard your system by making your machines intelligent using the Python ecosystem[M]. Packt Publishing Ltd, 2018.
- 周志华. 机器学习[M]. 清华大学出版社, 2016.
