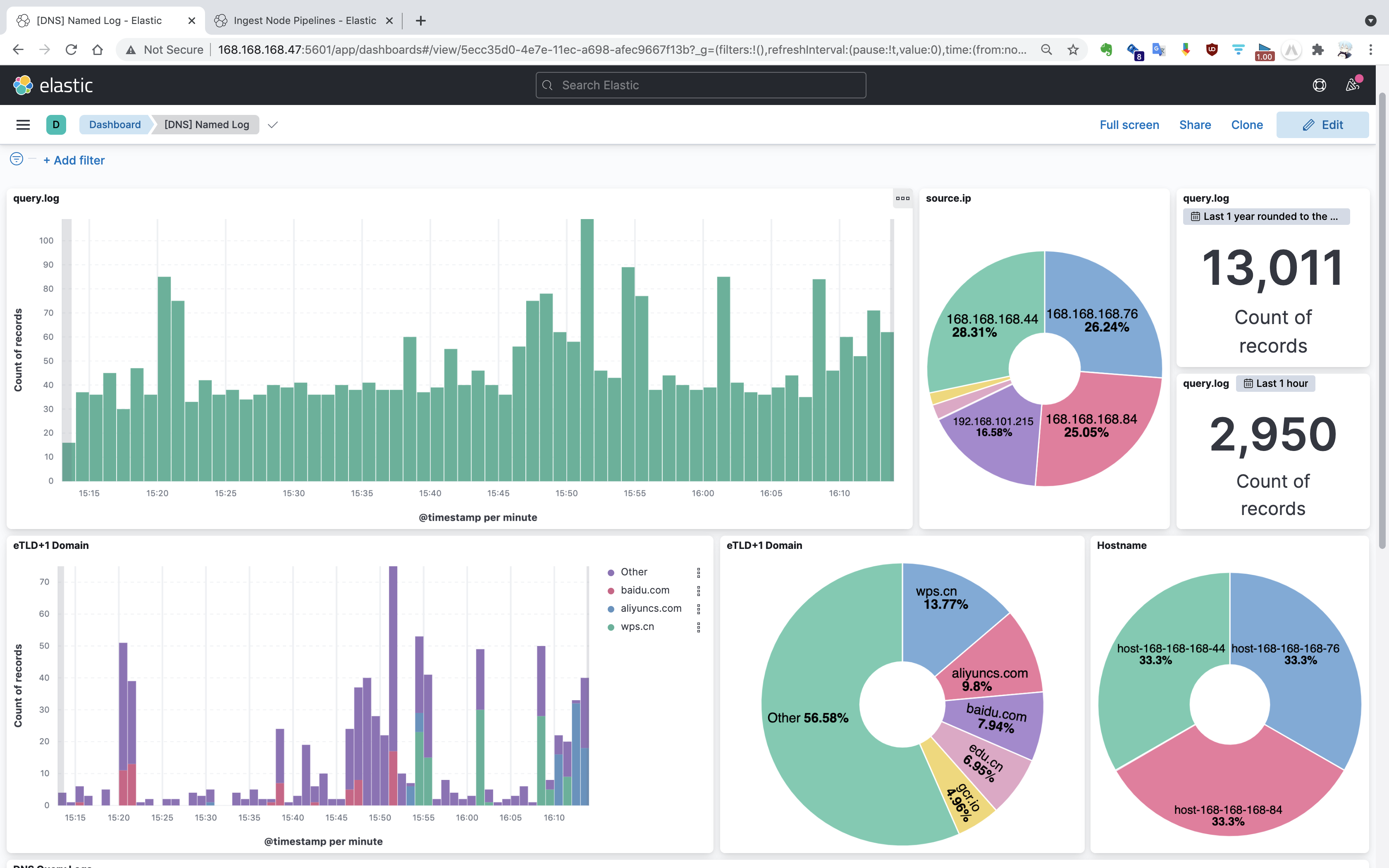
前期工作:基于 Bind9 搭建内网 DNS 服务器,使得在 /etc/resolv.conf 中配置了该服务器 IP 的节点或终端的 DNS 流量都会流经该服务器,为集群 DNS 流量采集提供了先决基础。同时,初步使用日志记录 DNS 查询请求(配置在 /etc/named.conf 中),后续可采用 Packetbeat/TShark 等工具主动捕获。DNS 查询日志内容格式如下:
1 2
30-Nov-2021 08:57:25.192 client @0x7f74f800b650 192.168.101.145#61323 (apisix.apache.org): query: apisix.apache.org IN A + (168.168.168.47) 30-Nov-2021 08:57:25.192 client @0x7f7514148d20 192.168.101.145#61325 (github.com): query: github.com IN A + (168.168.168.47)
为了推进后续的 DNS 流量分类研究工作,本文介绍了如何基于现有的 DNS 流量日志,使用 Elasticsearch 和 Kibana 搭建流量监测可视化平台。本文包含以下内容: