MapReduce 架构
本文讨论的 MapReduce 架构是 Hadoop 1.0 版本时的架构,从 Hadoop 2.0 开始,Hadoop 推出了资源管理框架 YARN。在 YARN 中,使用 ResourceManager 来负责容器的调度(任务运行在容器中),以及作业的管理。使用 NodeManager 来向 ResourceManager 汇报节点资源以及容器运行状态,NodeManager 负责创建并管理执行任务的容器。从职责方面,ResourceManager 等同于 JobTracker,NodeManager 等同于 TaskTracker。大多数的分布式框架都符合这种主从设计,如 HDFS 的 NameNode 和 DataNode、Spark 的 Driver 和 Executor 等。
以下是 MapReduce 架构和工作流程中的常用术语:
- Job(作业):是客户端需要执行的一个工作单元,包括输入数据、MapReduce 程序和配置信息;
- Task(任务):Hadoop 将作业分成若干个任务来执行,任务分为两类,即 Map 任务和 Reduce 任务;
- Map/Reduce:从执行阶段来看,Map 和 Reduce 代表两个大类阶段。从计算模型角度看,它们代表两个计算步骤。从代码层面看,它们是定义在 Mapper 和 Reducer 类中的函数;
- Mapper/Reducer:从执行阶段的详细划分来看,Mapper 和 Reducer 代表执行 map 与 reduce 函数的步骤。从代码层面看,这是定义在代码中的两个 Java 类。某些语境下,Mapper 可以指代 Map 任务,Reducer 同理。
与多数的大数据分布式框架相同,MapReduce 的架构也遵循主从结构:
- 运行在 HDFS NameNode 主节点上的 JobTracker 程序,负责接收从客户端提交的 Job,将其划分成 Map 任务和 Reduce 任务,分发给从节点 TaskTracker 执行。JobTracker 负责任务之间的协作,并通过 TaskTracker 发送来的心跳包维护集群的运行状态,以及作业进度信息。
- 多个运行在 HDFS DataNode 节点上的 TaskTracker 程序,负责执行 Map 任务和 Reduce 任务,直接与 HDFS 交互。每隔一段时间,TaskTracker 向 JobTracker 发送心跳包,汇报节点运行状态,以及任务完成进度。
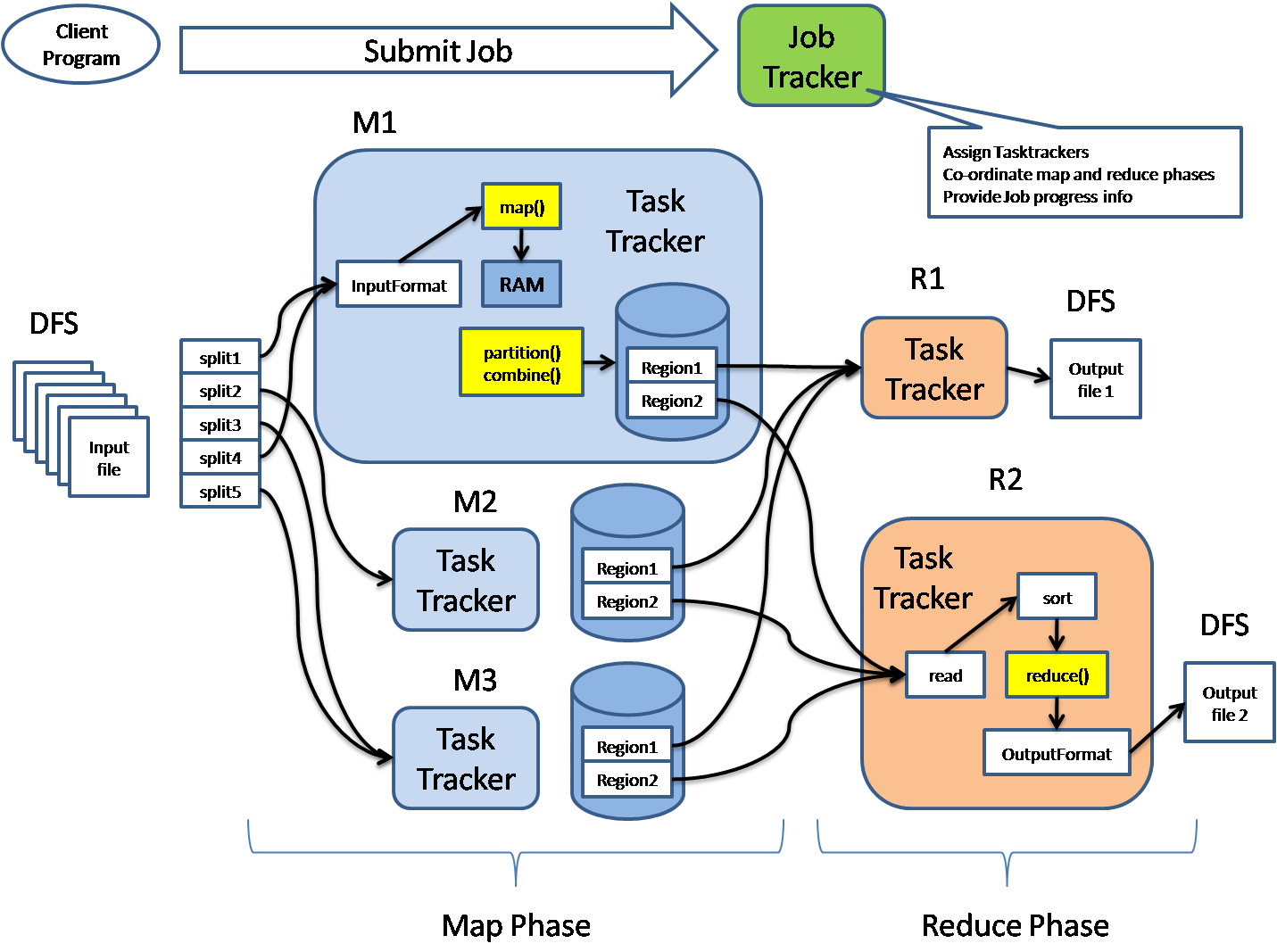
为了减少网络传输带来的性能影响,JobTracker 在分发 Map 任务时基于数据本地化优化(Data locality optimization)策略,将 Map 任务分发给包含此 Map 处理数据的从节点,并将程序 Jar 包发送给该 TaskTracker,遵循“运算移动,数据不移动”的原则。
新旧版本 API 说明
本文中的源码是 Hadoop 3.2.0 版本的源码,使用的是 Hadoop 新版 API。新版 API 位于 org.apache.hadoop.mapreduce 包下,旧版 API 位于 org.apache.hadoop.mapred 包下,两版 API 并不兼容,你可以在 这里 查看两者的区别。为保证向后兼容,Hadoop 并没有移除旧版 API,因此依赖库中两个版本并存,使用时要注意。
设计新版 API 的主要目的是给用户提供更加简洁优雅的接口,框架的核心代码并没有调整包,比如执行 Map 与 Reduce 任务的 MapTask 和 ReduceTask 类仍位于 org.apache.hadoop.mapred 包下。但由于使用了两套 API,在该类中你会经常看到以 Old/New 命名的类或方法,如 runNewMapper() 和 runOldMapper()。
在旧版本中,Mapper 与 Reducer 被定义为接口,而在新版本中被定义为具体类,并提供默认的 map 和 reduce 实现:仅是通过 context.write() 重新写回数据。旧版本的 Mapper 接口源码如下:
1 | public interface Mapper<K1, V1, K2, V2> extends JobConfigurable, Closeable { |
新版本中广泛使用上下文 Context 对象,整合了 OutputCollector、Reporter 和部分 JobConf 的功能,来实现与 MapReduce 系统的通信,如使用 context.write() 代替旧版的 output.collect() 功能。
新版本使用 Job 类替换旧版的 JobClient 类,实现作业控制,并使用统一的配置类 Configuration 来替换旧版的 JobConf 类,用于作业配置。因此,现在的一个 MapReduce 程序的入口函数可能如下所示:
1 | public static void main(String[] args) throws Exception { |
MapReduce 中的数据格式
MapReduce 工作过程中每个阶段的输入和输出数据都是以键值对的形式出现,如下表所示,表中的 k 与 v 代表了数据类型,不同下标代表不同的数据类型。
| 函数 | 输入 | 输出 | 备注 |
|---|---|---|---|
map() |
<$k_1$, $v_1$> | [<$k_2$, $v_2$>, …] | 一个输入分片被 Map 处理成一系列的键值对 |
reduce() |
<$k_2$, [$v_2$, …]> | <$k_3$, $v_3$> | Reduce 的输入键类型为 Map 后的输出键类型,输入值是键对应的值的集合 |
下面以统计词频程序 WordCount 为例,来说明 MapReduce 过程中的数据类型转换。
Mapper
在 Mapper 工作之前,框架从文件系统中读取文件并切分为分片,将数据转换为 <KEYIN, VALUEIN> 格式的键值对传给 map 函数。在 WordCount 程序中可以理解为形如 <行号, "a b c"> 的输入数据。实际上,输入键“行号”在实际代码中可能如下的 LongWritable 类型,一个可序列化的长整型偏移量(offset)。这是由 Hadoop 框架定义的数据类型。
1 | public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { |
注:Hadoop 提供了一套可优化网络序列化传输的基本类型,而不直接使用 Java 内置类型,这些类型位于 org.apache.hadoop.io 包中。上述代码中的 LongWritable 相当于 Java 的 Long 类型,Text 相当于 String 类型,IntWritable 相当于 Integer 类型。
map 函数将输入的文本串切分为一个个单词,输入的键值对被转换为 <KEYOUT, VALUEOUT> 格式的中间键值对输出。此时的输出键为单词,输出值为单词计数,默认为 1。即经由 Mapper 处理后,原本的“一行”数据被转换为了形如 [<"a", 1>, <"b", 1>, <"c", 1>] 的中间数据。
中间数据是暂时数据,不会存入 HDFS,但是会存入运行 Map 任务节点的本地磁盘,经过数据混洗后被 Reducer 端消费。
Reducer
由于 Reduce 任务与 Map 任务与不一定处于同一节点上,Reduce 任务会通过网络通信拉取多个 Map 任务产生的中间数据。数据从 Map 任务端传输给 Reduce 任务端的过程被称为数据混洗。
混洗之后传入给 Reducer 的输入键值对的值,是该键对应的值的集合(可迭代对象),如 <"a", [1, 2, 1]>。值可能为 2 是因为,为了减少磁盘写入和网络传输的数据量,Map 任务可能会在本地节点上预先聚合,这也就是 Combiner 所做的工作。
1 | public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { |
经过 reduce 函数处理后,单词的所有计数值被累加,输出形如 <"a", 4> 的键值对。
MapReduce 工作流程详解
MapReduce 将处理过程分成两个大类阶段:Map 阶段和 Reduce 阶段。在 Map 阶段,由于任务分发基于数据本地化原则,Map 任务运行在包含有该任务处理数据的节点上,数据存储在当前节点的 HDFS DataNode 中。因此,Map 阶段处理的都是本地数据,不需要进行网络传输。Map 阶段产生的中间数据将会暂存在当前节点上,Reduce 阶段需要从相关节点上拉取数据进行聚合运算,再将结果写入 HDFS。因此,Reduce 阶段既需要磁盘读写,也需要网络传输。
当然,MapReduce 在工作时还要细分为许多小阶段,下面这张图很好的展示了 MapReduce 的整个工作流程,具体包括:数据读入阶段、Mapper 处理阶段、优化性阶段 Combiner、中间数据分区 Partitioner 阶段、被称为 MapReduce “心脏”的数据混洗 Shuffle 阶段、Reducer 处理阶段以及数据写入阶段。
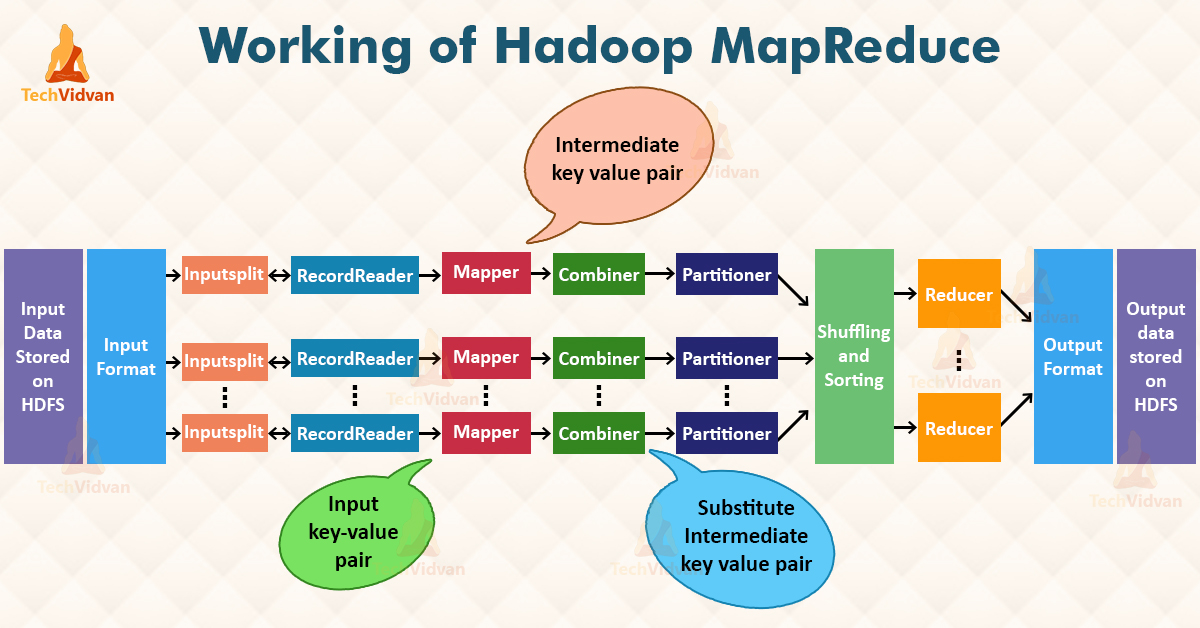
从大类阶段上划分,数据混洗之前的阶段都可以划分到 Map 阶段,因为这些步骤都是在本地节点上完成的,不涉及网络传输。而在数据混洗阶段,程序从本地或是集群上的其他节点拉取并拷贝 Mapper 产生的中间数据,提供给 Reducer 作为输入。因此,可以将包括数据混洗及其之后的步骤划分为 Reduce 阶段。事实上,数据混洗的相关类也被定义在 org.apache.hadoop.mapreduce.task.reduce 包下。
下面将结合源码详细介绍各个阶段的工作。
数据读入阶段
数据被 Mapper 处理前,需要先转换为 Mapper 支持的键值对类型,这个过程由 InputFormat 和 RecordReader 类完成。首先,由 InputFormat 类从 HDFS 读入文件并创建输入分片(Input Split),分片为等长的逻辑数据块,比如可能是形如 (input-file-path, start, offset) 的元组。
一个合理的分片大小应该与 HDFS 块大小保持一致,默认为 128 MB。Hadoop 会在分片数据所在的物理节点寻找一个空闲的 Map 槽,运行 Map 任务,由该任务运行用户自定义的 map 函数从而处理分片中的每条记录。此时,符合之前所说的数据本地化原则。一旦一个分片跨越两个物理块,由于 HDFS 的分布式存储特性,这两个块极可能位于不同的 DataNode 上,此时分片中的部分数据就需要通过网络传输到 Map 任务运行的节点。
1 | public abstract class InputFormat<K, V> { |
InputFormat 会为一个分片创建一个 RecordReader 对象,负责将输入分片转换为 Mapper 可处理的键值对。从数据视图角度看,输入数据字节流被转换为了面向记录的视图。
1 | public abstract class RecordReader<KEYIN, VALUEIN> implements Closeable { |
Mapper 阶段
在这个阶段,Mapper 会执行用户定义的 map 函数,并将输入的键值对转换为中间键值对序列。在 MapTask 类中,使用新版本的 Mapper 会直接调用 mapper.run() 方法运行,旧版本还需要由包装有 Mapper 的 MapRunner 来运行。新版的 API 中,允许用户覆盖 run() 方法,以及 Context 对象的生命周期方法,来做到对 Mapper 执行的完全控制。
1 | public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { |
注:Map 阶段的整个工作流程,可以在 MapTask 类的 run() 和 runNewMapper() 或 runOldMapper() 方法中清晰的一览。
Partitioner 阶段
与 Map 任务不同,Reduce 任务并不具备数据本地化的优势,单个 Reduce 任务的输入通常来自于所有 Mapper 的输出。因此,即使 Reduce 任务与某些个 Map 任务处于同一节点上,也不可避免的需要通过网络传输从其他节点上获取 Mapper 输出。
当只有一个 Reduce 任务时,这个 Reduce 任务会读取所有 Mapper 输出,此时对中间数据分区意义不大,因为所有 Mapper 输出都被写入同一文件。但当有多个 Reduce 任务时,为提高数据吞吐量,每个 Map 任务会针对输出进行分区(Partition),即为每个 Reduce 任务创建一个分区。同一个键对应的键值对记录都被划分在同一分区中,每个分区中可以包含许多键(及其对应的值)。并且,一个分区中的记录是按键排序的,这样,磁盘读取一个键的所有记录时能保证读取连续数据,而不是从零散的文件中再过滤数据。
数据溢写
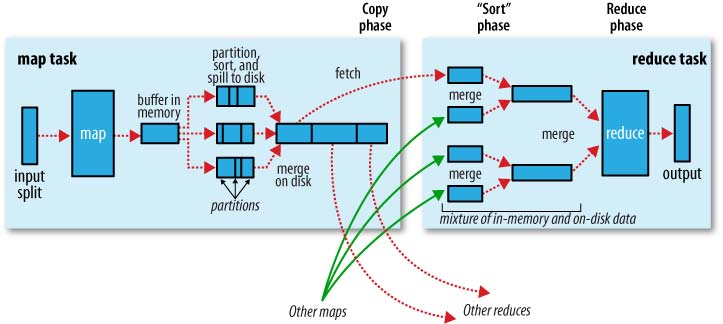
每个 Map 任务有一个环形内存缓冲区,缓冲区大小由 io.sort.mb 指定,默认 100MB。Mapper 产生的中间键值对记录将被先写入缓冲区,当达到缓冲区设定阈值时(io.sort.spill.percent,默认 80%),会开启一个线程将内容溢写(spill)到磁盘,由 mapred.local.dir 属性指定的目录。线程工作的同时,Mapper 的输出继续被写到缓冲区,如果在此期间缓冲区被写满,Mapper 将会阻塞直到溢写过程结束。
每次缓冲区达到溢出阈值,就会新建一个溢出文件,键值对会在内存中先按键排序然后写入文件。在任务完成前,溢出文件会不断合并并保证文件中数据是有序的。
数据溢写会写入运行 Map 任务节点的本地磁盘,并不会写入 HDFS(但 Reducer 的输出并不是这样)。这是因为,Map 任务运行的输入分片来自本地节点,输出也应写入本地节点,这样保证了整个 Map 任务的数据本地化。而写入 HDFS 则会为数据创建分布式副本,带来额外网络开销。更何况,Map 任务产生的输出只是暂时数据,任务执行完毕后会被删除。
源码分析
下面我们通过阅读 org.apache.hadoop.mapred.MapTask 类的相关源码,来加深对 Map 任务将中间键值对分区、排序存入磁盘过程的理解。Hadoop 使用 OutputCollector 将 Mapper 数据写入磁盘,由于继承/实现的类不同,MapTask 类中存在 Old/NewOutputCollector 两套新旧收集器。以新版 NewOutputCollector 为例,它的实现逻辑如下:
- 首先,创建一个排序收集器 collector,具体的排序逻辑在 MapOutputBuffer 类中,其实现了 IndexedSortable 接口的
compare()方法,按键进行排序; - 从作业上下文(配置)中获取 Reduce 任务总数;
- 当 Reduce 任务数大于一时,通过反射创建 Partitioner 类的实例,这个类可以是用户自定义的类,并在配置阶段注入;
- 如果 Reduce 任务数等于零(纯 Map 作业)或等于一,创建匿名内部类,返回的分区号为固定值,所有输出写到同一分区;
- 写入阶段通过收集器的
collect()方法,将键值对按照分区号写入对应分区。
1 | private class NewOutputCollector<K,V> extends RecordWriter<K,V> { |
Partitioner 类位于 org.apache.hadoop.mapreduce 包下,其作用是返回一个整型分区号,Map 任务将这个分区号作为写入哪个分区的标识。用户可以自定义分区函数,需要继承 Partitioner 类。通常,默认的分区函数 HashPartitioner 足够用了,它使用哈希函数,将键进行哈希后取非负(前置位补零)然后对 Reduce 任务总数取模。这样,能保证键相同的记录被分配至同一分区。
1 | public class HashPartitioner<K, V> extends Partitioner<K, V> { |
HashPartitioner 足够高效,但如果你执行的 MapReduce 作业发生数据倾斜的问题(如存在大部分相同键),可以考虑自定义分区函数,比如加入随机值。
Reduce 任务数设置
Hadoop MapReduce 的并行度取决于 Map 任务数量和 Reduce 任务数量。Map 任务数量不需要手动设置,原因是该数量等于输入文件被划分成的分片数,框架会为一个输入分片分配一个 Map 任务。Map 任务数据取决于输入文件的大小以及 HDFS 文件块的大小。默认情况下,输入分片大小与块大小保持一致,均为 128 MB。
Reduce 任务数量可以在作业配置时通过 job.setNumReduceTasks() 手动设置。默认情况下,只有一个 Reduce 任务,这对于本地小规模数据已经足够了。但在真实应用中,几乎所有作业都将它设置为一个较大的数字,否则,所有的中间数据都被传输给一个 Reduce 任务,作业处理极其低效。
为一个作业设置多少个 Reduce 任务数,与其说是一门技术,不如说更多是一门艺术。由于并行化程度提高,增加 Reducer 能缩短 Reduce 阶段整体耗时。并且,增加的 Reducer 对于解决数据倾斜问题通常能有很好的帮助。然而,如果配置了过多 Reducer,文件将被切分为更多小文件,磁盘 I/O 次数将显著增加,这又不够优化。相对于大批量的小文件,Hadoop 更适合处理少量的大文件。一条经验法则是,目标 Reducer 保持在每个运行 5 分钟左右,且产生至少一个 HDFS 块的输出比较合适。
Combiner 阶段
为了减少 Map 和 Reduce 任务之间的数据传输量,Hadoop 允许用户针对 Map 任务指定一个 Combiner 类。以统计词频程序为例,Mapper 输出的键值对 <单词,计数值> 的计数值初始均为一,此时可通过 Combiner 将相同键的值进行聚合,即计数值累加。这样,同一个 Mapper (来自同一输入分片)的处理数据将被提前聚合,既减少了磁盘写入数据量,也减少了需要通过网络传输给 Reducer 的数据量。因此 Combiner 也被称为 “Mini-reducer” 或 “Local-reducer”,意指在本地节点完成的。
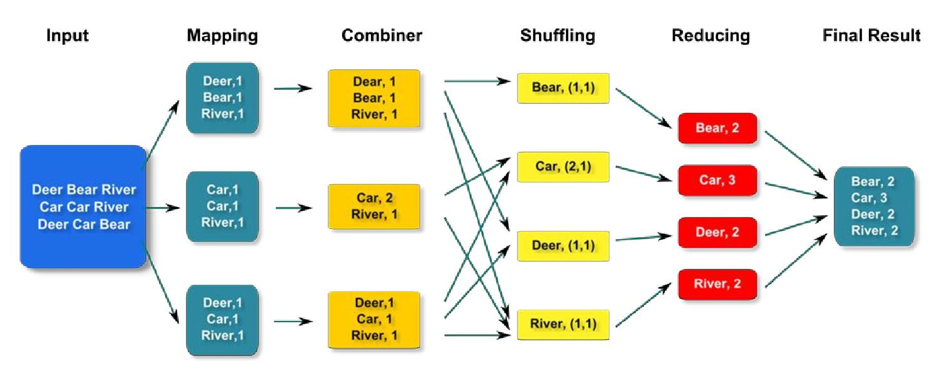
Combiner 工作在文件溢写的前后,具体是在 MapTask 的内部类的 sortAndSpill() 和 mergeParts() 方法中,由 combinerRunner.combine() 运行。在 Mapper 输出的键值对被溢写到磁盘之前,会在内存中按键排序,如果定义了 Combiner,它将在排序后的输出上运行,经过 Combiner 紧凑后的数据再写入磁盘。在溢出文件合并阶段,如果至少存在 3 个溢出文件(由 mapreduce.map.combine.minspills 属性指定),那么 Combiner 将会在文件合并时再次运行。因此,Combiner 可能会在 Mapper 输出上反复运行。如果只有 1 或 2 个溢出文件,此时说明 Mapper 输出吞吐量降低,因而不值得调用 Combiner 带来额外开销。
由于 Combiner 与 Reducer 聚合逻辑相同,Hadoop 没有提供额外的 Combiner 类,而是通过 Reducer 类复用。新版的 CombinerRunner 代码如下,它通过反射获取了一个 Reducer 实例,直接运行 Reducer 的 run() 方法进行数据聚合,聚合结果由上下文对象传入 OutputCollector 中,最后写入磁盘。
1 | protected static class NewCombinerRunner<K, V> extends CombinerRunner<K, V> { |
用户在声明作业配置时可以直接复用定义好的 Reducer 类。
1 | job.setMapperClass(TokenizerMapper.class); |
Shuffler 阶段
数据混洗(Shuffle)被称为是 MapReduce 的“心脏”,是奇迹发生的地方。从宏观上,它体现为从 Map 任务端到 Reduce 任务端的数据流处理过程,具体说即是 Mapper 产生的中间键值对被重新组织(排序、分区),写入到本地磁盘中(溢写),Reducer 从多个 Mapper 工作节点上拷贝、合并数据的过程。最终目的是将数据从 Mapper 端发送到 Reducer 端,中间过程则是 MapReduce 框架基于性能考量的优化过程。从下图你可以清晰的体会到为什么这个过程被称为“数据混洗”。
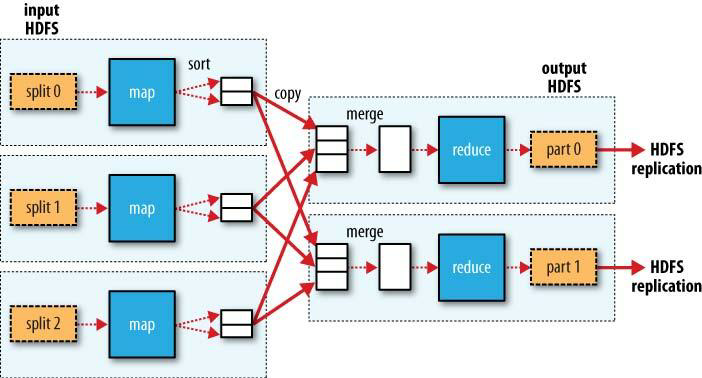
在微观上,Shuffle 被划分为了 Reduce 任务阶段的工作,定义在 org.apache.hadoop.mapreduce.task.reduce 包内。它是一个具体类,是框架定义的 ShuffleConsumerPlugin<K, V> 接口的内置实现类。从接口命名上可以体现出它作为 Mapper 端输出数据“消费者”的身份,“插件”则体现了它的可插拔特性,框架允许用户使用除了内置实现以外的三方插件。
在 ReduceTask 类的 run() 方法中通过反射获取了一个 Shuffle 类实例。job.getClass() 的第一个参数是三方插件的配置地址,第二个值 Shuffle.class 即为默认的内置实现类。
1 | public class ReduceTask extends Task { |
Shuffle 类的 run() 方法,是数据混洗步骤真正的具体实现。
源码分析
在一个 Map 任务完成后,会通过心跳包通知 JobTracker,这样,JobTracker 就能获取 Map 输出与主机位置之间的映射关系,Reduce 任务中的一个线程定期询问 JobTracker 以获取 Map 输出位置,直到获取所有输出位置。当一个 Map 任务完成后,Reduce 任务就可以开始复制了,这就是 Reduce 任务的复制(copy)阶段。此过程由并发线程完成,默认是 5 个线程,由 mapreduce.reduce.shuffle.parallelcopies 属性指定。
1 | public class Shuffle<K, V> implements ShuffleConsumerPlugin<K, V>, ExceptionReporter { |
Shuffle 使用名为 Fetcher 的线程类进行数据复制,如果 Reduce 任务恰好就处于运行 Map 任务的节点上,此时不需要网络通信,直接通过 LocalFetcher 获取本地数据。否则,使用 Fetcher 通过 HTTP 通信拉取相关节点上的数据。
1 | class Fetcher<K, V> extends Thread { |
注:拉取后的数据是写入内存还是写入磁盘,是由 MapOutput 类的 shuffle() 方法完成的,该类拥有两个具体子类:InMemoryMapOutput 和 OnDiskMapOutput。
如果 Map 任务输出相当小,会被复制到 Reduce 任务的 JVM 内存缓冲区中,一旦内存缓冲区达到阈值,Map 输出会被复制到磁盘。随着磁盘上副本增多,后台线程会将它们合并为更大的、按键排好序的文件,这就是 Reduce 任务的合并阶段(merge)。这个阶段将合并 Map 输出,并维持其按键排序。合并的数据可能来自于内存缓冲区和磁盘文件。
合并阶段按照预先设定的合并因子(默认为 10),每趟合并 10 个文件,所以合并过程是循环进行的。为减少磁盘读写次数,最后一轮的文件合并(包含所有数据)不再写入磁盘,而是直接传送给 Reducer 处理。
Reducer 阶段
在 Reducer 阶段,对已排序的输出中的每个键调用 reduce 函数。此阶段的输出直接写到输出文件系统,一般为 HDFS,还可以是数据库。如果采用 HDFS,由于 Reduce 任务运行所在的节点也运行 DataNode,所以第一个块副本将被写到本地磁盘中。
用户需要继承 Reducer 并重写 reduce 函数,函数的输入值入参是值的可迭代对象,框架会从文件系统中读取输入键对应的值集合,传入给 reduce 函数。
1 | public class Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { |
与 Mapper 类似,框架也允许用户覆盖 run() 方法,以及 Context 对象的生命周期方法。
数据写入阶段
数据写入阶段,由 OutputFormat 负责检验作业的输出规范,如输出目录是否已存在。如果写入到文件系统,则由实现子类 FileOutputformat 的 setOutputPath() 方法负责从作业配置中读取输出目录。由 OutputFormat 创建的 RecordWriter 对象负责将 Reducer 产生的键值对数据写到输出文件,每个 Reducer 对应一个文件。此过程无需创建分片。
1 | public abstract class OutputFormat<K, V> { |
MapReduce 的局限
在 MapReduce 的工作过程中,框架需要频繁地读写文件系统,MapReduce 作业往往又都是数据密集型的,因此大量的中间数据会被往复地写入、读取、合并排序后又写入磁盘。大量的磁盘 I/O 导致 MapReduce 的耗时往往是分钟级、甚至是小时级的。受到 MapReduce 诞生年代的约束,昂贵的内存迫使用户将 Hadoop 集群部署在廉价的商用机器集群上,使用磁盘来进行数据的缓存。大规模的分布式部署使得 MapReduce 程序具有高容错性和良好的横向扩展性优势。
时至今日,用户对数据处理延迟的忍耐性越来越低,在大规模数据批处理之上又诞生了实时性要求极高的流处理系统。不管是 Spark Streaming 还是 Flink 都能做到秒级甚至是毫秒级的响应,MapReduce 因为其性能局限已经跟不上时代的需求。
MapReduce 的函数本身是无状态的,这意味着并不是所有工作 MapReduce 都能胜任,比如需要状态共享和参数依赖的机器学习模型训练算法。尽管 MapReduce 可以通过文件存储状态,但这样带来的性能开销是巨大的。相反,Spark 作为一个基于内存迭代式的大数据计算引擎很适合这样的场景,其提供了有状态的流来应对需要状态共享的作业,通过 updateStateByKey() 和 mapWithState() 状态管理函数共享状态。状态被保存在内存中,后续访问直接从内存中读取。据 Spark 官方统计的 Spark 运行逻辑回归机器学习算法的运行时间要优于 hadoop 一百倍。这也让 Spark 提供机器学习库 Spark MLlib 成为可能。
MapReduce 框架要求用户编写底层的 map 和 reduce 函数,这对于数据分析师是一个考验,Spark SQL 允许数据分析师使用 SQL 语言处理数据,由框架负责将其翻译成底层执行步骤。而且,编写底层函数这样的控制粒度不够灵活,对于一个复杂的作业来说,可能要由多个 MapReduce 作业组合而成,这样又会引入额外的中间数据读写开销。相比之下,Spark 编程模型更灵活,提供了丰富的 Transformation 和 Action 算子。性能方面,Spark 会为作业构建逻辑执行计划图(DAG),并针对其步骤进行优化,减少数据混洗阶段的 I/O 次数。
不管怎么说,MapReduce 作为第一代分布式计算引擎,其后诞生的分布式框架都是在其基础上的演进,因此有必要对 MapReduce 工作原理做个详细了解。Spark 由批处理起家,延续了 MapReduce 编程模型的设计思路。下一节我们将介绍 Spark 的运行原理。
