封装
面向对象程序设计(Object-oriented programming,缩写 OOP)是指一种程序设计范型,它强调一切行为都是基于对象(object)完成的,而对象则指的是类(class)的实例。对象被作为程序的基本单元,数据和行为方法封装在其中,以提高软件的重用性、灵活性和扩展性,对象的行为方法可以访问和修改对象的数据。通过对象之间的相互协作,完成复杂的程序功能。面向对象编程语言具备封装、抽象、继承、多态等特性。
封装,又称信息隐藏,是指利用抽象数据类型(ADT)将数据和基于数据的操作封装在一起,尽可能地隐藏内部细节,只暴露一些公共接口与外部发生交互。面向对象编程语言使用类进行封装,数据和基于数据的操作对应于类的属性和方法。
具备封装性的面向对象程序设计隐藏了方法的具体执行步骤,取而代之的是对象之间的消息传递。举个例子,假设一个“歌唱家”想要“唱歌”,她当然知道自己该如何发声,但其他人没有必要了解她发声的细节,只管欣赏她美妙的歌喉。
1 | /* 一个面向过程的程序会这样写: */ |
访问限制
使用封装能够对成员属性和方法进行精确的访问控制,通常来说,成员会依照它们的访问权限被分为3种:公有成员、私有成员以及保护成员,保护成员是指可以被子类访问的成员。有的语言更进一步:Java 专门提供了 public、private、protected 和缺省四个级别的访问权限控制关键字。Python 则更提倡开放,尽管没有强制要求,但也建议程序员使用带有下划线的命名风格来规范属性和方法的访问权限。
在 Python 中,非下划线开头的属性称为公有属性,单下划线或双下划线开头的属性称为私有属性,双下划线开头的私有属性不会被子类可见,Python 社区很少提及受保护的属性。PEP 8 提倡对于非公有方法和属性使用单个下划线开头,只有在避免子类命名冲突时才采用双下划线开头,这是因为解释器会改写双下划线开头的属性,改写为类名 + 变量名的格式。比如下面代码中的 __v3 就被改写为 _C__v3:
1 | class C: |
即便如此,Python 也不能严格保证私有属性不能被外部访问。子类之所以不能访问父类的双下划线开头的属性,只是因为改写后的属性名称不相符而已。
1 | class B(C): ... |
对于私有属性,《Effective Python》也建议尽量少用双下划线开头的属性,宁可让子类更多地访问父类的单下划线开头的私有属性,也不要使用双下划线命名限制子类访问,并在文档中把这些属性的合理用法告知子类的开发者。
为什么 Python 不从语法上严格保证私有属性的私密性呢?因为 Python 社区认为开放要比封闭好。而且,Python 提供了一些操作属性的特殊方法,如 __getattr__,使得无法隔绝私有属性的访问,既然如此,那么就默认开发者遵循 Python 编码风格和规范,能够按需操作类内部的属性。
抽象
抽象是解决问题的法宝。良好的抽象策略可以简化问题的复杂度,并且提高系统的通用性和可扩展性。在面向对象程序设计出现直接,面向过程的程序设计多是针对的过程抽象。所谓过程抽象是将问题域中具有明确功能定义的操作抽取出来,将其定义为函数。而面向对象程序设计针对的是数据抽象,是较过程抽象更高级别的抽象方式,通过将描述客体的属性和行为绑定在一起,实现统一的抽象,从而达到对现实世界客体的真正模拟。
类是具有相同属性(数据元素)和行为(功能)的对象的抽象。因此,对象的抽象是类,类的具体化就是对象,也可以说类是抽象数据类型,对象是类的实例。类具有属性,它是对象的状态的抽象,用数据结构来存储类的属性。类具有操作,它是对象的行为的抽象,用操作名和实现该操作的方法来描述。类的每一个实例对象都具有这些数据和操作方法。
抽象可以具有层次性,由类的继承结构所体现。高层次的抽象封装行为,为低层次的抽象提供签名,可以不实现具体细节,比如抽象基类或接口。低层次的抽象实现具体细节,提供对象实例化功能。通过抽象的层次性和结构性,可以减小问题求解的复杂度。
从 C++ 2.0 起(1989 年发布),这门语言开始使用抽象类指定接口。Java 的设计者选择不支持类的多重继承,这排除了使用抽象类作为接口规范的可能性,因为一个类通常会实现多个接口。但是,Java 设计者提供了 interface 这个语言结构,以更明确的方式定义接口,并允许一个类实现多个接口 —— 这是一种多重继承。自 Java 8 起,接口可以提供方法实现,即默认方法,使得 Java 中的接口与 C++ 和 Python 中的抽象基类更像了。但它们之间有个关键的区别:Java 的接口没有状态。Java 之后使用最广泛的 JVM 语言要数 Scala 了,它就实现了性状(trait)。不管怎么说,让我们先从抽象基类开始,了解 Python 中的高层次抽象类型。
抽象基类
在引入抽象基类(Abstract base classes,缩写 ABC)之前,Python 就已经很成功了。Python 倡导使用鸭子类型和协议,忽略对象的真正类型,转而关注对象有没有实现所需的方法、签名和语义。这使得 Python 编码更加宽松,不需要严格的类型限制。因此抽象基类并不是 Python 的第一选择,大概也因为此,直至 Python 语言诞生 15 年后,Python 2.6 中才引入抽象基类。
但这并不意味着抽象基类一无是处,相反,它被广泛应用于 Java、C# 等面向对象语言中。抽象基类的常见用途是实现接口时作为基类使用,它与普通基类的区别在于:
- 抽象基类不能实例化;
- 具体子类必须实现抽象基类的抽象方法。
正是由于抽象基类限定了子类必须实现特定的方法,它被经常用于构建框架。你可以在 Python 标准库的 collections.abc 和 numbers 模块中见到抽象基类的身影。
Python 中定义抽象基类需要用到标准库提供的 abc 模块,该模块由 PEP 3119 – Introducing Abstract Base Classes 提案所引入。它支持两种方式定义抽象基类,一种是使用 abc.ABCMeta 作为元类。声明元类的 metaclass 关键字参数是 Python 3 引入的,在此之前 Python 2 还得使用 __metaclass__ 类属性。另一种是直接继承 abc.ABC 类,需要注意 ABC 的类型仍然是 ABCMeta。
1 | from abc import ABC, ABCMeta |
一般通过继承 ABC 来简单地创建抽象基类,当遇到可能会导致元类冲突的多重继承时,也可以使用 ABCMeta 作为元类来定义抽象基类。
abc 模块还提供了用于声明抽象方法的装饰器 @abstractmethod。抽象方法定义体中通常只有文档字符串。在导入时,Python 不会检查抽象方法是否被实现,而是在实例化时检查。如果没有实现,将抛出 TypeError 异常提示无法实例化抽象类。如下所示:
1 | from abc import abstractmethod |
抽象方法可以有实现代码,但即便实现了,子类也必须覆盖抽象方法。通常这样做的目的是在子类中使用 super() 复用基类的方法,为它添加功能而不是从头实现。其实在抽象基类出现之前,抽象方法会抛出 NotImplementedError 异常,提示子类必须实现该抽象方法。
除了 @abstractmethod 之外,abc 模块还定义了 @abstractclassmethod、@abstractstaticmethod 和 @abstractproperty 装饰器,可用于装饰类方法、静态方法和特性。但自 Python 3.3 起这三个装饰器就被废弃了,因为可以使用装饰器堆叠达到同样的效果。在堆叠时,要保证 @abstractmethod 是最内层的装饰器,即最靠近函数定义体。如下所示:
1 | class MyABC(ABC): |
注:PEP 3119 提案同时也引入并定义了集合类型的抽象基类,包括容器和迭代器类型,可以参考提案的 ABCs for Containers and Iterators 一节。这些集合类型被统一定义在 collections.abc 模块中。为了减少加载时间,Python 3.4 在 collections 包之外实现了这个模块,即 _collections_abc.py,所以在导入时要使用 collections.abc 与 collections 分开导入。
注册虚拟子类
Python 中的抽象基类还有一个重要的实用优势:可以使用 register 将某个类声明为一个抽象基类的“虚拟”子类,这样就不用显式继承。这打破了继承的强耦合,与面向对象编程的惯有知识有很大出入,因此在使用继承时要多加小心。
虚拟子类不会从抽象基类中继承任何方法和属性,但类型检查函数 issubclass() 和 isinstance() 都会通过。Python 不会检查虚拟子类是否符合抽象基类的接口,即便实例化时也不会检查,但会在调用时抛出异常。因此,为了避免运行时错误,虚拟子类要实现抽象基类的所有抽象方法。
注册虚拟子类的 register() 方法可以作为普通函数调用,也可以作为装饰器使用。如下定义的抽象基类 Drawable 中定义了一个抽象方法 draw,可以随机抽取一个元素。我们实现了一个扑克类 Poker,使用装饰器形式将 Poker 类注册为 Drawable 的虚拟子类。
1 | import random |
使用 @Drawable.register 与直接调用方法的 Drawable.register(Poker) 效果相同,这样即使不用显式继承,Poker 类也会被解释器视为 Drawable 抽象基类的子类型。
1 | poker = Poker() |
注册虚拟子类被广泛应用于 collections.abc 模块中,比如将内置类型 tuple、str、range 和 memoryview 注册为序列类型 Sequence 的虚拟子类:
1 | Sequence.register(tuple) |
__subclasshook__ 钩子方法
有时甚至不需要手动注册,抽象基类也能将一个类绑定为虚拟子类。比如 Poker 类会被绑定为 collections.abc.Sized 的虚拟子类:
1 | from collections.abc import Sized |
这是由于 Sized 抽象基类内部实现了一个名为 __subclasshook__ 的钩子方法。这个方法会去检查类中是否包含 __len__ 方法,如果包含,那么类型检查 issubclass() 和 isinstance() 会返回 True。
同理,我们可以为 Drawable 类实现此钩子方法,方法的两个参数指代的均是类对象 __class__。这样即使不手动注册,实现了 draw 方法的扭蛋机类 Capsule 也会被判定为 Drawable 的子类:
1 | class Drawable(ABC): |
实际上,很少需要为自己编写的抽象基类实现 __subclasshook__ 方法,虽然这符合 Python 对于“鸭子类型”的定义,但这样做可靠性很低。好比说,不能指望任何实现了 draw 方法的类都是 Drawable 类型(可随机抽取元素),因为 draw 可能还指代其他语义,比如画图。
类型检查函数 issubclass() 和 isinstance() 之所以会返回 True,是由于定义在 ABCMeta 类中的 __subclasscheck__ 和 __instancecheck__ 特殊方法会覆盖其行为。在 ABCMeta 的构造方法中定义了一些 WeakSet 类型的类属性:_abc_registry、_abc_cache 和 _abc_negative_cache,它们会动态的存放抽象基类的虚拟子类(类型检查时会动态添加)。可以通过调试接口 _dump_registry() 查看一个抽象基类的虚拟子类。
1 | Drawable._dump_registry() |
注:ABCMeta 类的 Python 源码可以在 _py_abc 模块中查看。CPython 提供了一套基于 C 语言的更高效实现,仅在其导入失败时,才导入 _py_abc 模块中的 ABCMeta。
白鹅类型
最早提出“鸭子类型”的 Alex Martelli 建议在鸭子类型的基础上添加“白鹅类型”。白鹅类型是指,只要 cls 是抽象基类,即 cls 的元类是 abc.ABCMeta,就可以使用 isinstance(obj, cls)。事实上,虚拟子类就是一种白鹅类型,当我们向抽象基类注册一个虚拟子类时,ABCMeta 会将该类保存在抽象基类的类属性中,以供类型检查使用。
虚拟子类是抽象基类动态性的体现,也是符合 Python 风格的方式。它允许我们动态地改变类的属别关系。抽象基类定义了一系列方法,并给出了方法应当实现的功能,在这一层次上,“白鹅类型”能够对类型进行甄别。当一个类继承自抽象基类时,语言本身限制了该类必须完成抽象基类定义的语义;当一个类注册为虚拟子类时,限制则来自于编写者自身(成年人)。两种类都能通过“白鹅类型”的校验,不过虚拟子类提供了更好的灵活性与扩展性。例如,一个框架允许第三方插件时,采用虚拟子类即可以明晰接口,又不会影响内部的实现。
自定义的抽象基类
在各类编程语言中,基础的数据结构都必不可少,比如链表、堆栈、集合等,对于这些数据结构,语言会对它们进行抽象,定义接口并设计一套继承体系。Java 将这些数据结构统称为容器(意指用于容纳数据),从最底层的 List、Set、Map 等接口,到 AbstractList、AbstractSet、AbstractMap 等抽象类,再到最上层的 ArrayList、HashSet、HashMap 等具体实现类,越靠近上层的类方法越丰富,但底层的接口和抽象类是框架的骨架,构成了整个容器框架。同时,接口和抽象类也是体现 Java 语言多态性(向上转型)的重要设计。
Python 的容器抽象基类定义在 collections.abc 模块中,其 UML 类图如下所示:
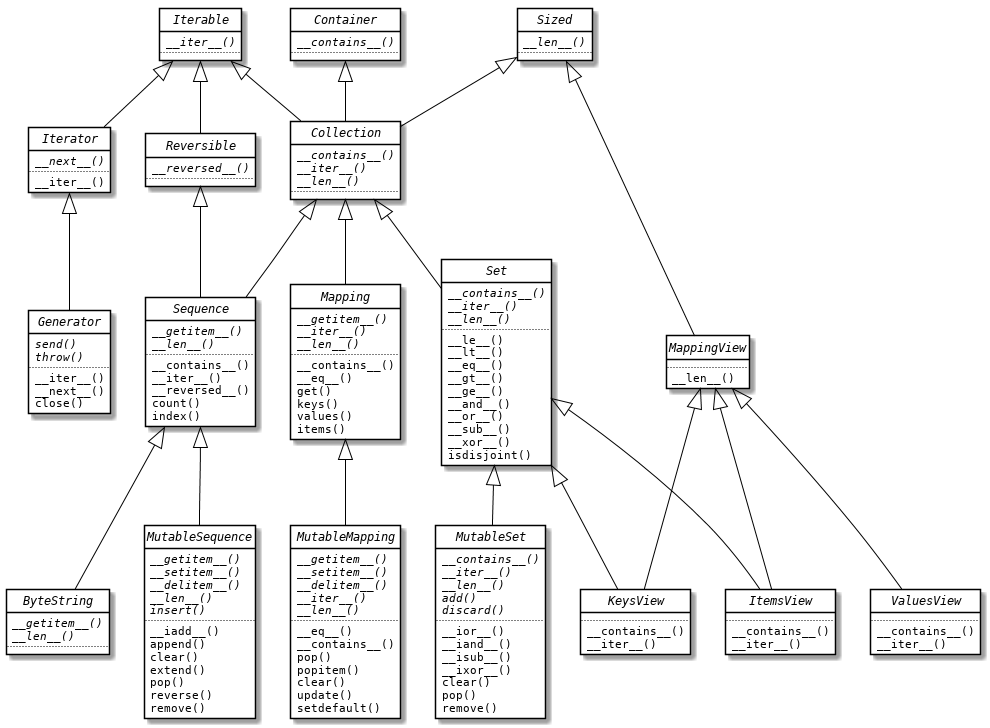
下面我们尝试使用 Python 中的抽象基类实现一个自定义的容器类型。为了简化,这个容器类型仅支持新增 push() 和删除 pop() 两个操作。由于不同子类的具体实现不同,比如栈是先进后出,队列是先进先出,所以这两个方法被定义为抽象方法。此外还提供了检视容器元素的 inspect() 方法,由于实现逻辑相同,因此 inspect() 可以是具体方法。
1 | from abc import ABC, abstractmethod |
可以看到,抽象基类既可以拥有抽象方法,也可以拥有具体方法。代码中的初始化方法 __init__ 和 inspect() 方法都是具体方法,但子类依然可以覆盖具体方法,或者使用 super() 调用它们进行功能增强。
自定义的抽象基类的子类
接下来我们实现 Container 抽象基类的两个具体子类:栈和队列。
1 | class Stack(Container): |
由于具体子类继承自抽象基类 Container,所以在类声明时必须明确指定类扩展自 Container 类。并且覆盖抽象基类中的两个抽象方法。栈和队列的 pop() 行为不同,栈满足先进后出,而队列满足先进先出,并在容器为空时均抛出 IndexError 异常。接下来验证栈和队列的特性:
1 | stack = Stack([1, 2]) |
何时使用抽象基类
对于简单的个人应用,优先使用现有的抽象基类,而不是自己编写抽象基类,因为这很容易造成过度设计。毕竟对于 Python 来说,“简单”永远是这门语言的核心,滥用抽象基类会造成灾难性后果,太注重语言的表面形式对于以实用和务实著称的 Python 可不是好事。
抽象基类可以约束各个子类实现相同的一套 API。除此之外,抽象基类的一个用途是运行时的类型检查,可以使用 isinstance() 检查某个对象是否是抽象基类的子类型,即是否实现了特定的接口。这便于我们对于不同的情形进行分支处理或异常捕获。
尽管抽象基类使得类型检查变得更容易了,但也不该过度使用它。Python 的核心在于它是一门动态语言,如果处处都强制实现类型约束,那么会使代码变得复杂且丑陋。我们应该拥抱 Python 的灵活性。
因此对于抽象基类的使用,要着重声明:除非构建的是允许用户扩展的框架,否则不要轻易定义抽象基类。日常使用中,我们与抽象基类的联系应该是创建现有抽象基类的子类。当你拥有像创建新的抽象基类的想法时,首先尝试使用常规的鸭子类型来解决问题。
继承
面向对象编程语言的一个重要功能就是“继承”,它可以使得在现有类的基础上,无需编写重复代码就可以实现功能的扩展。继承体现了从一般到特殊的过程。
通过继承创建的新类称为“子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类”。在某些面向对象语言中,一个子类可以继承自多个父类,这称为多重继承。Python 是一门支持多重继承的语言。
Python 的继承句法是,在类声明的括号中添加父类名,如 class C(Base): 声明了类 C 继承自基类 Base。当声明多重继承时,使用逗号隔开,如 class C(BaseA,BaseB):。
子类会继承父类的非私有属性和方法,包括类属性。这里的私有属性是指以双下划线开头且不以双下划线结尾命名的属性,由于 Python 的名称改写机制,这类私有属性将会被改写为“类名 + 属性名”的格式,所以不能被子类通过原有名称访问。
如下,B 类派生自 A 类,继承了 A 类的所有非私有属性和方法:
1 | class A: |
子类可以覆盖父类的属性和方法,或者使用 super() 调用父类方法,在原有方法基础上添加新功能。super() 的一个重要用途是用于初始化方法 __init__ 中。如下所示:
1 | class B(A): |
多重继承
Python 支持多重继承。人们对于多重继承褒贬不一,C++ 中对于多重继承的滥用一直饱受诟病,借鉴自 C++ 的 Java 选择直接移除了多重继承特性,采用接口(Interface)作为代替,并取得了巨大的成功。事实证明,接口是一种更加优雅的多重继承解决方案。
多重继承首先要解决的问题就是潜在的命名冲突,如果一个类继承自两个不相关的类,这两个类拥有实现不同的同名方法,那么该调用哪一个?这种冲突被称为“菱形问题”。为了解决这个问题,Python 会按照特定的顺序遍历继承图。这个顺序称为方法解析顺序(Method Resolution Order,缩写 MRO)。类有一个名为 __mro__ 的类属性,它的值是一个元组,按照方法解析顺序存放各个超类的名称。
__mro__ 方法解析顺序
我们定义一个继承结构,类 D 继承自类 B 和 C,而类 B 和 C 又都继承自类 A。
1 | class A: |
从继承结构上来看,这是一个菱形结构,会存在调用同名方法的二义性。那么,调用 D 实例的 speak() 方法会去调用哪个父类呢?
答案是会调用 B 的 speak() 方法。D 类的 __mro__ 属性如下,访问 D 的方法,会按照 D -> B -> C -> A 的顺序进行解析。
1 | d = D() |
注:方法解析顺序不会列出虚拟子类的被注册超类。因此虚拟子类也不会从被注册超类中继承任何方法。
super() 调用链
在使用 super() 调用父类方法时,也遵循方法解析顺序。如果父类中的方法也包含 super() 语句,则按照方法解析顺序调用下一个父类的方法(下一个父类可能不是当前父类的直接父类)。比如如下添加了 super() 语句的 speak() 方法打印如下:
1 | class A: |
按照 D -> B -> C -> A 的方法解析顺序,D 中的 super() 方法跳转到 B,B 中的 super() 方法跳转到 C(而不是 B 的直接父类 A),C 中的 super() 方法再跳转到 A。由于 super() 语句在 print 语句之前,最终呈现出的打印顺序是方法解析顺序的出栈顺序。
方法解析顺序的单调性
方法解析顺序不仅考虑继承图,还考虑子类声明中所列的超类顺序。如果 D 类声明为 class D(B, C):,那么 D 类一定会先于 B、C 类被搜索,且 B 类一定先于 C 类被搜索。我们将这种 D -> B -> C 的顺序称为方法解析顺序的单调性。 用户在定义继承关系时必须要遵循单调性原则。
Python 方法解析顺序采用的 C3 算法会检查方法解析顺序的单调性。简单地说,C3 算法的基本逻辑是,每定义好一个继承关系顺序,算法会将所有顺序按照满足单调性的方式整合起来,如果整合过程出现冲突,算法会抛出错误。
如下所示,由于定义 B 类时声明为 class B(A):,所以 B 的解析顺序要先于 A,然而在使用 class C(A, B): 声明 C 类时,A 的解析顺序又先于 B,因此发生冲突,抛出异常。
1 | class A: ... |
在 Python 标准库中,最常使用多重继承的是 collections.abc 模块,其中的类都定义为抽象基类。抽象基类类似于 Java 中的接口声明,只不过它可以提供具体方法。因此在 collections.abc 模块中频繁使用多重继承并没有问题,它为 Python 的集合类型构建了一个继承体系。然而,滥用多重继承容易得到令人费解和脆弱的设计。《Effective Python》中也提到:只在使用混入时才使用多重继承。为此,有必要先介绍一下混入类。
混入类
除了传统的面向对象继承方式,还流行一种通过可重用组件创建类的方式,那就是混入(mixin),这在 Scala 和 JavaScript 使用颇多。如果一个类的作用是为多个不相关的子类提供方法实现,从而实现重用,但不体现 “is-a” 语义,应该把这个类明确定义为混入类。从概念上讲,混入不定义新类型,只是打包方法,便于重用。因此,混入类绝对不能实例化,而且具体类不能只继承混入类。
Python 没有提供定义混入类的专有关键字,而是推荐在名称末尾加上 “Mixin” 后缀。而在 Scala 中,使用 trait(特性)关键字来声明混入类,TypeScript 中则使用 implements 关键字来继承混入类。
抽象基类可以实现具体方法,因此也可以作为混入使用。collections.abc 模块中的抽象基类在一定程度上可以被视为混入类,它们都声明了 __slots__ = () 语句,表明了混入类不能具有实例属性,即混入类不能被实例化。但是,抽象基类可以定义某个抽象类型,而混入做不到,因此,抽象基类可以作为其他类的唯一基类,而混入绝不能作为唯一超类。但是,抽象基类有个局限是混入类没有的,即:抽象基类中提供具体实现的抽象方法只能与抽象基类及其超类中的方法协作。
一些三方库和框架中也有用到混入,比如 Django 框架,我截取了 Django 视图模块的一小部分源码,以便更好的理解混入类与多重继承的关系。
Django 源码
在 Django 中,视图是可调用对象,它的参数是表示 HTTP 请求的对象,返回值是一个表示 HTTP 响应的对象。我们要关注的是这些响应对象。响应可以是简单的重定向,没有主体内容,为我们导向另一个 url,也可以是复杂的网页内容,需要使用 HTML 模版渲染,最终呈现在浏览器终端上。为此,Django 框架提供了重定向视图 RedirectView,以及模版视图 TemplateView。
我们将注意力放在 TemplateView 类上,它继承自三个类,从左到右分别是模版响应混入类 TemplateResponseMixin、上下文混入类 ContextMixin,以及视图基类 View。
1 | class TemplateView(TemplateResponseMixin, ContextMixin, View): |
从类型上来说,TemplateView 依然是一个视图类型。View 是所有视图的基类,提供核心功能,如 dispatch 方法。RedirectView 由于不需要渲染,所以只继承了 View 类。
1 | class View: |
两个混入类 TemplateResponseMixin 和 ContextMixin 并不代表某一特定类型,而是打包了若干属性和方法,此类方法又不是 RedirectView 所需要的,因此不能定义在 View 基类中。TemplateResponseMixin 提供的功能只针对需要使用模版的视图,除了 TemplateView 还提供给其他视图,例如用于渲染列表的 ListView 视图以及默认视图 DetailView 等。
1 | class TemplateResponseMixin: |
Django 基于类的视图 API 是多重继承的一个优雅示例,尤其是 Django 的混入类易于理解:各个混入类的目的明确,且都以 “Mixin” 作为后缀。
继承的最佳实践
明确使用继承的目的:在决定使用继承之前,首先明确这么做的目的。如果是为了继承重用代码,那么组合和委托也可以达到相同效果。《设计模式:可复用面向对象软件的基础》一书中明确指出:“优先使用对象组合,而不是类继承”。组合体现的是 “has-a” 语义,与继承相比,组合的耦合性更低,可扩展性更高。继承并不是银弹,继承意味着父类与子类的强耦合性,一旦父类接口发生变化,所有子类都会受到影响。如果继承用错了场合,那么后期的维护可能是灾难性的。但如果目的是继承接口,创建子类型,实现 “is-a” 关系,那么使用继承是合适的。接口继承是框架的支柱,如果类的作用是定义接口,就应该明确定义为抽象基类,就像 collections.abc 模块所做的那样。
不要继承多个具体类:最多只有一个具体父类,也可以没有。也就是说,除了这一个具体父类之外,其余都是抽象基类或混入。并且,如果抽象基类或混入的组合被经常使用,那么就可以考虑定义一个聚合类,使用易于理解的方式将他们结合起来,就如同 collections.abc 模块中定义的 Collection 类:class Collection(Sized, Iterable, Container):。
只在使用混入时才使用多重继承:这比上一条要更加严苛,尽管抽象基类有时可被视为混入类。不管怎么说,如果不是开发框架,尽量避免使用多重继承,如果不得不用多重继承,请使用混入类。混入类不会破坏现有的继承结构树,它就像小型的可插拔的扩展接口坞,目的不是声明 “is-a” 关系,而是为子类扩展特定功能。所以有时也将混入类称为混入组件。
在声明多重继承自混入类和基类时,先声明混入类,最后声明基类:这是由于,在定义混入类时使用 super() 是普遍的。为了保证继承自混入类和基类的子类,在调用方法时会执行基类的同名方法,需要先声明混入类再声明基类。这样,按照方法解析顺序的单调性,混入类中的 super() 方法会调用到基类中的方法。
如下定义了一个属性只能赋值一次的字典,为其属性赋值时,按照方法解析顺序,会先调用混入类的 __setitem__ 方法,执行到 super() 语句,调用基类 UserDict 的 __setitem__ 方法进行设值。
1 | from collections import UserDict |
使用 collections 模块子类化内置类型:内置类型的原生方法使用 C 语言实现,不会调用子类中覆盖的方法。比如,如下 DoubleDict 中定义的 __setitem__ 方法并不会覆盖初始化方法 __init__ 中的设值方法。因此,需要定制 list、dict 或 str 类型时,应该使用 collections 模块中的 UserList、UserDict 或 UserString 等。这些类是对内置类型的包装,会把操作委托给内置类型 —— 这是标准库中优先选择组合而不是继承的又一例证。如果所需的行为与内置类型区别很大,那么子类化 collections.abc 中的抽象基类自己实现或许更加容易。
1 | class DoubleDict(dict): |
