前言
Java 拥有功能和性能都非常强大的日志库,但另一方面,Java 日志库依赖看起来丰富的让人眼花缭乱。相信大家或多或少都有这样的疑问,Log4j,SLF4J,Logback,Log4j2 这些日志框架我该如何选择?它们彼此间又有什么关系?本篇文章将介绍这些日志库的历史演进和之间的关系,方便你选择最适合的日志库。文章最后还有日志库使用的最佳实践。
历史
Log4j (Log For Java) 可以当之无愧地说是 Java 日志框架的元老,1999 年发布首个版本,2012 年发布最后一个版本,2015 年正式宣布终止,至今还有无数的系统在使用 Log4j,甚至很多新系统的日志框架选型仍在选择 Log4j。
然而老的不等于好的,在 IT 技术层面更是如此。尽管 Log4j 有着出色的历史战绩,但早已不是 Java 日志框架的最优选择。
在 Log4j 被 Apache Foundation 收入门下之后,由于理念不合, Log4j 的作者 Ceki Gülcü 离开并开发了 SLF4J 和 Logback。
SLF4J (Simple Log Facade For Java) 因其优秀的性能和理念很快受到了广泛欢迎,2016 年的统计显示,GitHub 上的热门 Java 项目中,SLF4J 是使用率第二名的类库(第一名是 Junit)。
Logback 则吸取了 Log4j 的经验,实现了很多强大的新功能,再加上它和 SLF4J 能够无缝集成,也受到了欢迎。
在这期间,Apache Logging 则一直在关门憋大招,Log4j2 在 beta 版鼓捣了几年,终于在 2014 年发布了 GA 版,不仅吸收了 Logback 的先进功能,更通过优秀的锁机制、LMAX Disruptor、”无垃圾”机制等先进特性,在性能上全面超越了 Log4j 和 Logback。
Log4j 1.x
Log4j (Log For Java) 是在 Logback 出现之前被广泛使用的日志库,由 Gülcü 于 2001 年发布,后来成为 Apache 基金会的顶级项目。Log4j 在设计上非常优秀,对后续的 Java Log 框架有长久而深远的影响,也产生了 Log4c、Log4s、Log4perl 等到其他语言的移植。Log4j 的短板在于性能,在Logback 和 Log4j2 出来之后,Log4j 的使用也减少了。
Commons Logging
Commons Logging,简称 JCL,是 Apache 下属项目。JCL 是一个 Log Facade,只提供 Log API,不提供实现,然后有 Adapter 来使用 Log4j 或者 JDK 中自带的 JUL(Java Util Logging)作为 Log Implementation。
不同的项目可能各自使用了不同的日志库,如果你的项目依赖的其他项目各自使用了不同的日志库,你想控制日志行为,就需要针对每个日志库都写一个配置文件,那岂不是很麻烦?所以这个时候 JCL 就出现了。
在程序中日志创建和记录都是用 JCL 中的接口,而真正运行时会搜索当前 ClassPath 中有什么实现,如果有 Log4j 就是用 Log4j,如果啥都没有则使用 JDK 的 JUL。这样,在你的项目中,还有第三方的项目中,大家记录日志都使用 JCL 的接口,然后最终运行程序时,可以按照自己的需求(或者喜好)来选择使用合适的 Log Implementation。比如你想使用 Log4j,就添加 Log4j 的依赖并编写一个 Log4j 的配置文件(通常命名为 log4j.properties)。
SLF4J/Logback
SLF4J (Simple Logging Facade for Java) 和 Logback 也是 Gülcü 创立的项目,其创立主要是为了提供更高性能的实现。其中,SLF4j 是类似于 JCL 的 Log Facade,Logback 是类似于 Log4j 的 Log Implementation。
SLF4J 出现的缘由是 Gülcü 认为 JCL 的 API 设计得不好,容易让使用者写出性能有问题的代码。比如在用 JCL 输出一个 debug 级别的 log:
1 | logger.debug("start process request, url: " + url); |
这个有什么问题呢?一般生产环境 log 级别都会设到 info 或者以上,那这条 log 是不会被输出的。然而不管会不会输出,这其中都会做一个字符串连接操作,然后生产一个新的字符串。如果这条语句在循环或者被调用很多次的函数中,就会多做很多无用的字符串连接,影响性能。所以 JCL 的最佳实践推荐这么写:
1 | if (logger.isDebugEnabled()) { |
显然作为 API 来说这太为繁琐,所以 SLF4J 提供了新的 API,方便开发者使用:
1 | logger.debug("start process request, url: {}", url); |
这样的话,在不输出 log 的时候避免了字符串拼接的开销;在输出的时候需要做一个字符串 format,代价比手工拼接字符串大一些,但是可以接受。
而 Logback 则是作为 Log4j 的取缔者来开发的,提供了性能更好的实现,以及异步 logger,Filter 等更多的特性。
Log4j2
现在有了更好的 SLF4J 和 Logback 正慢慢取代 JCL 和 Log4j,然而维护 Log4j 的人不想坐视用户一点点被 SLF4J /Logback 蚕食,所以 Log4j2 诞生了。Log4j2 和 Log4j1.x 并不兼容,设计上很大程度上模仿了 SLF4J/Logback,性能上也获得了很大的提升。Log4j2 也做了 Facade/Implementation 分离的设计,分成了 log4j-api 和 log4j-core。
Facade & Implementation
JCL、SLF4J 和 Log4j2 日志框架都使用了 GoF 设计模式中的门面模式(Facade Pattern),将接口和实现分离,定义统一的接口,而实现可以由用户自由选择。现在我们有了三个流行的 Log Facade,以及多个 Log Implementation,那么该如何配合使用呢?
SLF4J
Gülcü 是个追求完美的人,他决定让 SLF4J 和这些 Log 之间都能够方便的互相替换,所以做了各种 Adapter 和 Bridge 来连接:
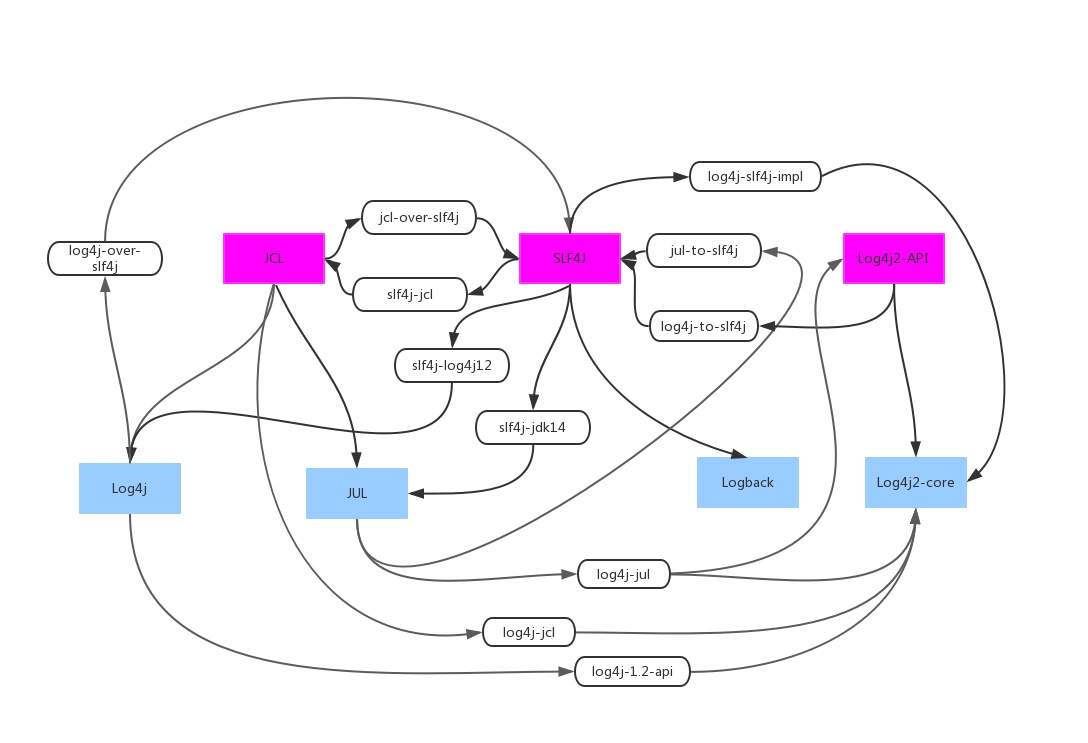
有趣的是,唯独没有 slf4j-over-log4j2 的桥接库,而且 log4j-to-slf4j 和 log4j-slf4j-impl 也是由 Apache 自己开发的。
slf4j-api 只是 Log Facade 的依赖,添加了该依赖意味着在编码时你能够使用 Logger log = LoggerFactory.getLogger(Main.class); 和 log.info("hello, {}", "world"); 这种方式。除此之外,还需要添加 Log Implementation 的依赖。
下图是 SLF4J官网 介绍可以绑定的日志实现框架。其中 slf4j-simple 是为小项目提供的简单实现;logback-classic 是官方的原生实现,不需要额外的适配器。而 slf4j-log4j12 和 slf4j-jdk14 分别是适配到 Log4j 和 JUL 的依赖,JUL 由于是 JDK 自带所以不需要额外依赖,而 Log4j 则还需要添加自己的底层实现依赖。

下面这张图展示了 SLF4J 绑定不同日志实现框架需要的依赖:
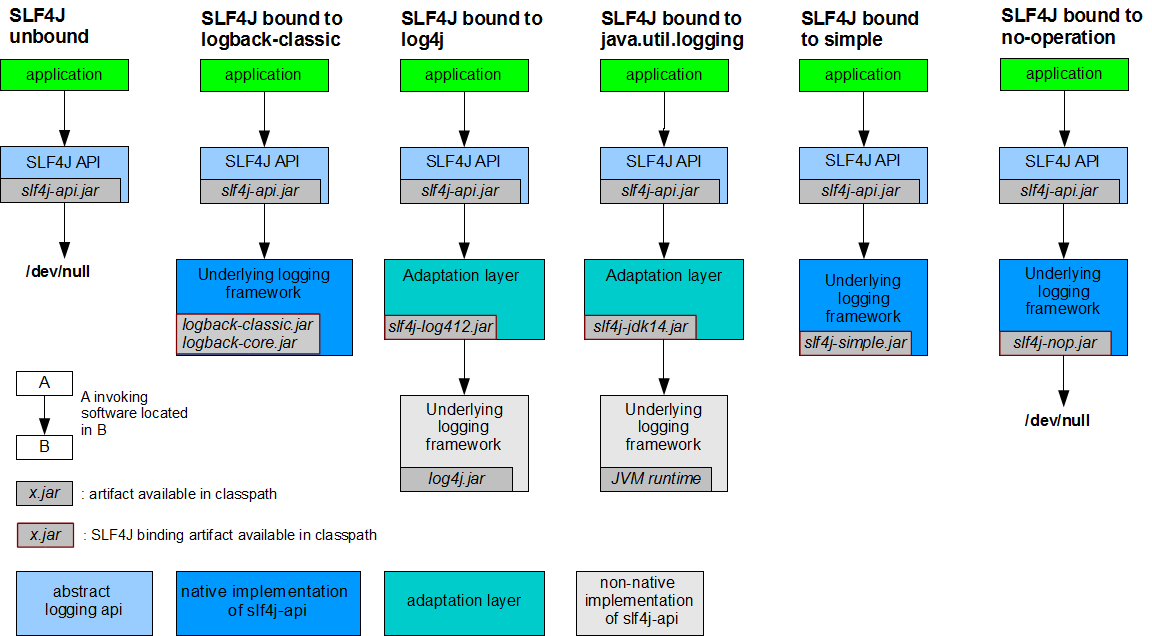
Log4j2
关于 Log Facade 选择 SLF4J 还是 Log4j2,个人觉得要看项目需求。总的来说 SLF4J 的兼容性更好,日志实现可以随意搭配使用;虽然 Log4j2 可以通过 log4j-to-slf4j 桥接到 SLF4J 再使用其他的 Log Implementation,但这必然带来多余的性能消耗。
而 Log4j2 的优点则在于性能,在 Is it worth to use slf4j with log4j2 这个问题中推荐直接面向 Log4j2 API 编程,理由如下:
- Message API
- Lambdas for lazy logging
- Log any Object instead of just Strings
- Garbage-free: avoid creating varargs or creating Strings where possible
- CloseableThreadContext automatically removes items from the MDC when you’re finished with them
Logback 和 Log4j2 都宣称自己是 Log4j 的后代,一个是出自同一作者,另一个则是在名字上根正苗红。撇开血统不谈,比较一下 Log4j2 和 Logback:
- Log4j2 比 Logback 更新。Log4j2 的 GA 版在 2014 年底才推出,比 Logback 晚了好几年,这期间 Log4j2 确实吸收了 SLF4J 和 Logback 的一些优点(比如日志模板),同时应用了不少的新技术
- 由于采用了更先进的锁机制和 LMAX Disruptor 库,Log4j2 的性能优于 Logback,尤其是在多线程环境下和使用异步日志的环境下
- 二者都支持 Filter(应该说是 Log4j2 借鉴了 Logback 的 Filter),能够实现灵活的日志记录规则(例如仅对一部分用户记录 DEBUG 级别的日志)
- 二者都支持对配置文件的动态更新
- 二者都能够适配 SLF4J, Logback 与 SLF4J 的适配应该会更好一些,毕竟省掉了一层适配库
- Logback 能够自动压缩/删除旧日志
- Logback 提供了对日志的 HTTP 访问功能
- Log4j2 实现了“无垃圾”和“低垃圾”模式。简单地说,Log4j2 在记录日志时,能够重用对象(如String等),尽可能避免实例化新的临时对象,减少因日志记录产生的垃圾对象,减少垃圾回收带来的性能下降
这是 Apache 官方提供的同步和异步写日志时的性能对比图:
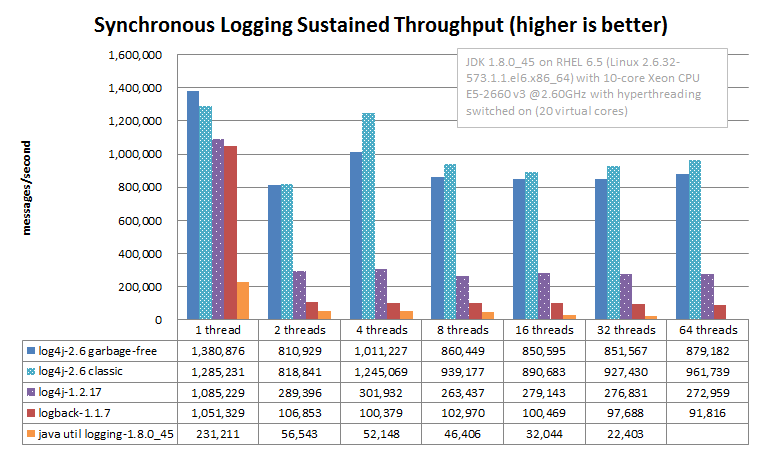
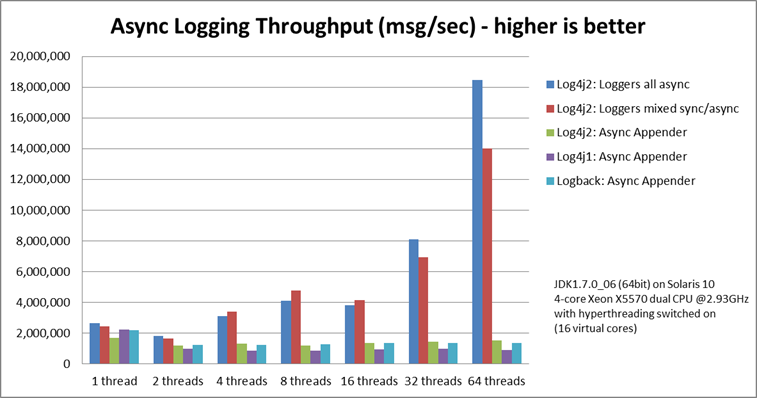
所以综上所诉,个人的看法是:如果对性能有要求,且 Log Implementation 想选用 Log4j2 的话,推荐 Log Facade 直接使用 Log4j2 API。
最佳实践
总是使用 Log Facade,而不是具体 Log Implementation
正如之前所说的,使用 Log Facade 可以方便的切换具体的日志实现。而且,如果依赖多个项目,使用了不同的 Log Facade,还可以方便的通过 Adapter 转接到同一个实现上。如果依赖项目使用了多个不同的日志实现,就麻烦的多了。
具体来说,现在推荐使用 Log4j2 API 或者 SLF4j,不推荐继续使用 JCL。
只添加一个 Log Implementation 依赖
毫无疑问,项目中应该只使用一个具体的 Log Implementation,建议使用 Logback 或者 Log4j2。如果有依赖的项目中,使用的 Log Facade 不支持直接使用当前的 Log Implementation,就添加合适的桥接器依赖。
总是为 Log Implementation 依赖设置 optional 和 runtime scope
在项目中,Log Implementation 的依赖强烈建议设置为 runtime scope,并且设置为 optional。例如项目中使用了 SLF4J 作为 Log Facade,然后想使用 Logback 作为 Implementation,那么使用 POM 文件应该这么写:
1 | <dependency> |
设为 optional,依赖不会传递,这样如果你的项目被别的项目依赖,它就不会引入不想要的 Log Implementation 依赖,即使用你提供的库的用户可以自定义 Log Implementation;
Scope 设置为 runtime,是为了防止开发人员在项目中直接使用 Log Implementation 中的类,而不适用 Log Facade 中的类,即编码时程序员只可见 Log Facade 层面而不必关注实现层面。
如果有必要,排除依赖的第三方库中的 Log Impementation 依赖
这是很常见的一个问题,第三方库的开发者未必会把具体的日志实现或者桥接器的依赖设置为 optional,然后你的项目继承了这些依赖。然而具体的日志实现未必是你想使用的,比如他依赖了 Log4j,你想使用 Logback,这样程序在运行时会检测到有多个日志实现类,如下图。另外,如果不同的第三方依赖使用了不同的桥接器和 Log 实现,也容易形成环。
1 | SLF4J: Class path contains multiple SLF4J bindings. |
这种情况下,推荐的处理方法,是使用 exclude 来排除所有的这些 Log 实现和桥接器的依赖,只保留第三方库里面对 Log Facade 的依赖。
1 | <dependency> |
另外,在 IntelliJ IDEA 中,可以使用 Show Maven Dependencies 查看依赖关系图,可以方便的搜索依赖并 exclude 掉。
避免为不会输出的 log 付出代价
Log 库都可以灵活的设置输出界别,所以每一条程序中的 log,都是有可能不会被输出的。这时候要注意不要额外的付出代价。
先看两个有问题的写法:
1 | logger.debug("start process request, url: " + url); |
第一条是直接做了字符串拼接,所以即使日志级别高于 debug 也会做一个字符串连接操作;第二条虽然用了 SLF4J/Log4j2 中的懒求值方式来避免不必要的字符串拼接开销,但是 toJson() 这个函数却是都会被调用并且开销更大。
推荐的写法如下:
1 | logger.debug("start process request, url:{}", url); // SLF4J/LOG4J2 |
日志中尽量避免输出行号,函数名等字段
原因是,为了获取语句所在的函数名,或者行号,log 库的实现都是获取当前的 stacktrace,然后分析取出这些信息,而获取 stacktrace 的代价是很昂贵的。如果有很多的日志输出,就会占用大量的 CPU。在没有特殊需要的情况下,建议不要在日志中输出这些这些字段。
正确做法是使用日志打印的类名和内容定位到代码位置。
1 | public class Main { |
