前言 为了免去繁杂的环境配置工作,提供开箱即用的 Spark + Hadoop 快捷部署方案。本教程基于 BitNami 项目的成熟镜像方案,搭建 Spark Docker 集群,并在原有镜像基础上,构建了安装有对应版本 Hadoop 的镜像。
镜像已提交至 Docker Hub 官方仓库中,可通过如下命令拉取:
1 docker pull s1mplecc/spark-hadoop:3
构建镜像的所需文件也已提交至 GitHub:s1mplecc/spark-hadoop-docker 。
实验环境
操作系统 MacOS Mojave,命令行工具:Terminal + Zsh
Docker Desktop for Mac,内置 Docker CLI client 与 Docker Compose
Spark Docker 镜像:bitnami-docker-spark ,Spark 版本:3.1.2
Hadoop 版本:hadoop-3.2.0
部署 Spark 集群 拉取镜像 BitNami 是一个开源项目,现已被 VMware 公司收购,其宗旨是简化在个人终端、Kubernetes 和云服务器等环境上的开源软件的部署。其已为 Docker Hub 社区提供了数百个容器镜像方案,其中的 Redis、MongoDB 等热门镜像更是超过了十亿次下载。
bitnami/spark 镜像也已超过百万次下载,这是一个成熟的 Spark Docker 方案。此外选择它的重要原因是它的文档齐全,且更新频率快,目前的最新版本基于 Spark 官方发行的最新版本 Spark 3.1.2。
1 2 3 4 ➜ docker pull bitnami/spark:3 ➜ docker images REPOSITORY TAG IMAGE ID CREATED SIZE bitnami/spark 3 67ed3ae333e0 4 days ago 1.29GB
注:此镜像基于 bitnami/minideb 基础镜像,这是 BitNami 构建的极简 Debian 系统镜像。Debian 由于系统稳定且内核占用资源小的优势,非常适合作为服务器操作系统。
以集群方式运行 为了模拟 Spark 集群,采取一主二从的部署方式,使用 Docker Compose 对容器集群进行统一编排管理。
首先,在本地新建一个工作目录,我的路径为 ~/docker/spark,在该目录下编写 docker-compose.yml 配置文件。基于 bitnami/spark 提供的配置文件,我做了一些修改,包括:
hostname:容器实例主机名;volumes:挂载本地目录 ~/docker/spark/share 到容器目录 /opt/share;ports:开放 4040 和从节点 Spark Web UI 端口。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 version: '2' services: spark: image: docker.io/bitnami/spark:3 hostname: master environment: - SPARK_MODE=master - SPARK_RPC_AUTHENTICATION_ENABLED=no - SPARK_RPC_ENCRYPTION_ENABLED=no - SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no - SPARK_SSL_ENABLED=no volumes: - ~/docker/spark/share:/opt/share ports: - '8080:8080' - '4040:4040' spark-worker-1: image: docker.io/bitnami/spark:3 hostname: worker1 environment: - SPARK_MODE=worker - SPARK_MASTER_URL=spark://master:7077 - SPARK_WORKER_MEMORY=1G - SPARK_WORKER_CORES=1 - SPARK_RPC_AUTHENTICATION_ENABLED=no - SPARK_RPC_ENCRYPTION_ENABLED=no - SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no - SPARK_SSL_ENABLED=no volumes: - ~/docker/spark/share:/opt/share ports: - '8081:8081' spark-worker-2: image: docker.io/bitnami/spark:3 hostname: worker2 environment: - SPARK_MODE=worker - SPARK_MASTER_URL=spark://master:7077 - SPARK_WORKER_MEMORY=1G - SPARK_WORKER_CORES=1 - SPARK_RPC_AUTHENTICATION_ENABLED=no - SPARK_RPC_ENCRYPTION_ENABLED=no - SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no - SPARK_SSL_ENABLED=no volumes: - ~/docker/spark/share:/opt/share ports: - '8082:8081'
现在可以启动 Spark Docker 集群了。在工作目录下,执行如下命令:
1 2 3 4 5 ➜ docker-compose up -d [+] Running 3/3 ⠿ Container spark-spark-1 Started 1.0s ⠿ Container spark-spark-worker-2-1 Started 1.1s ⠿ Container spark-spark-worker-1-1 Started 1.1s
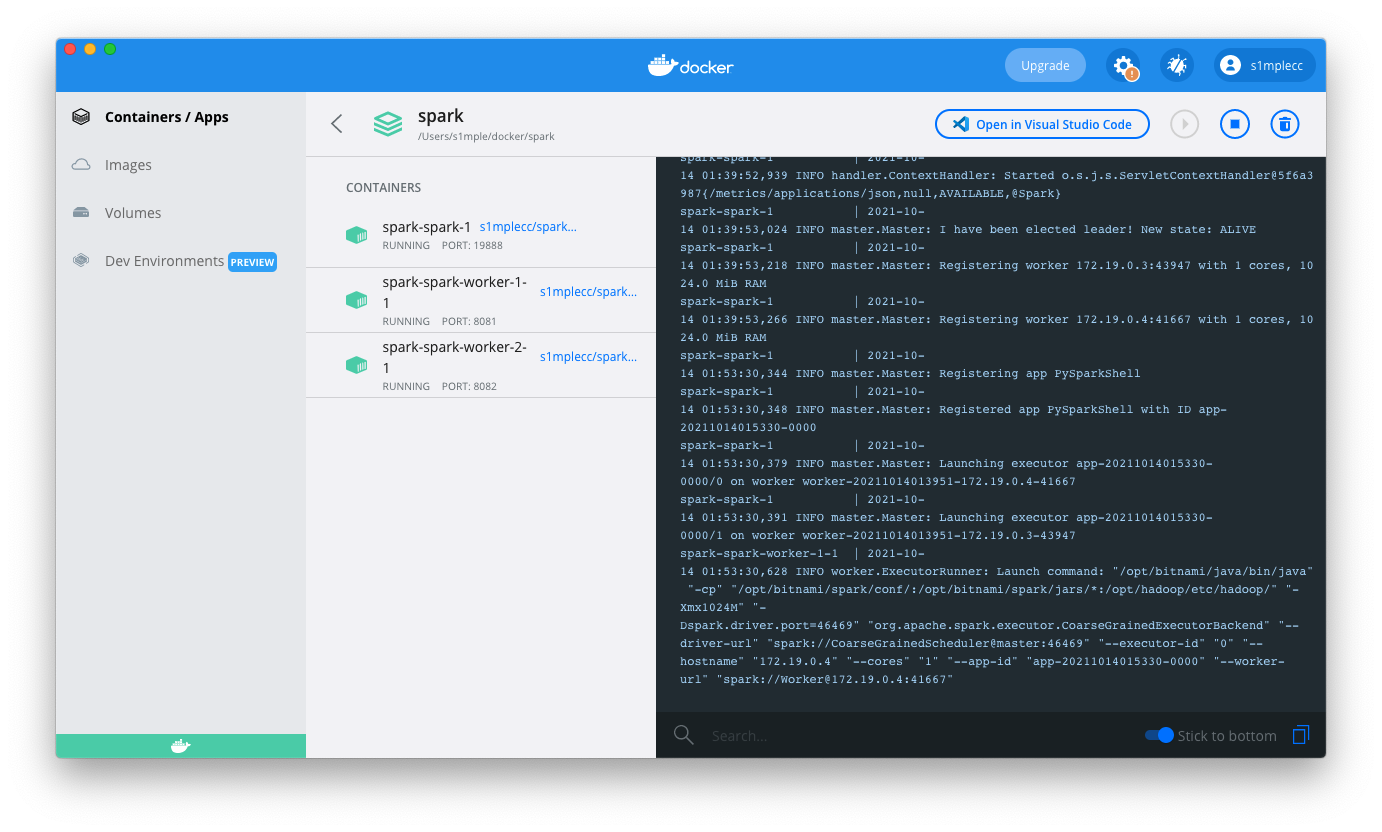
启动后的集群可以在 Docker Desktop 中进行查看:
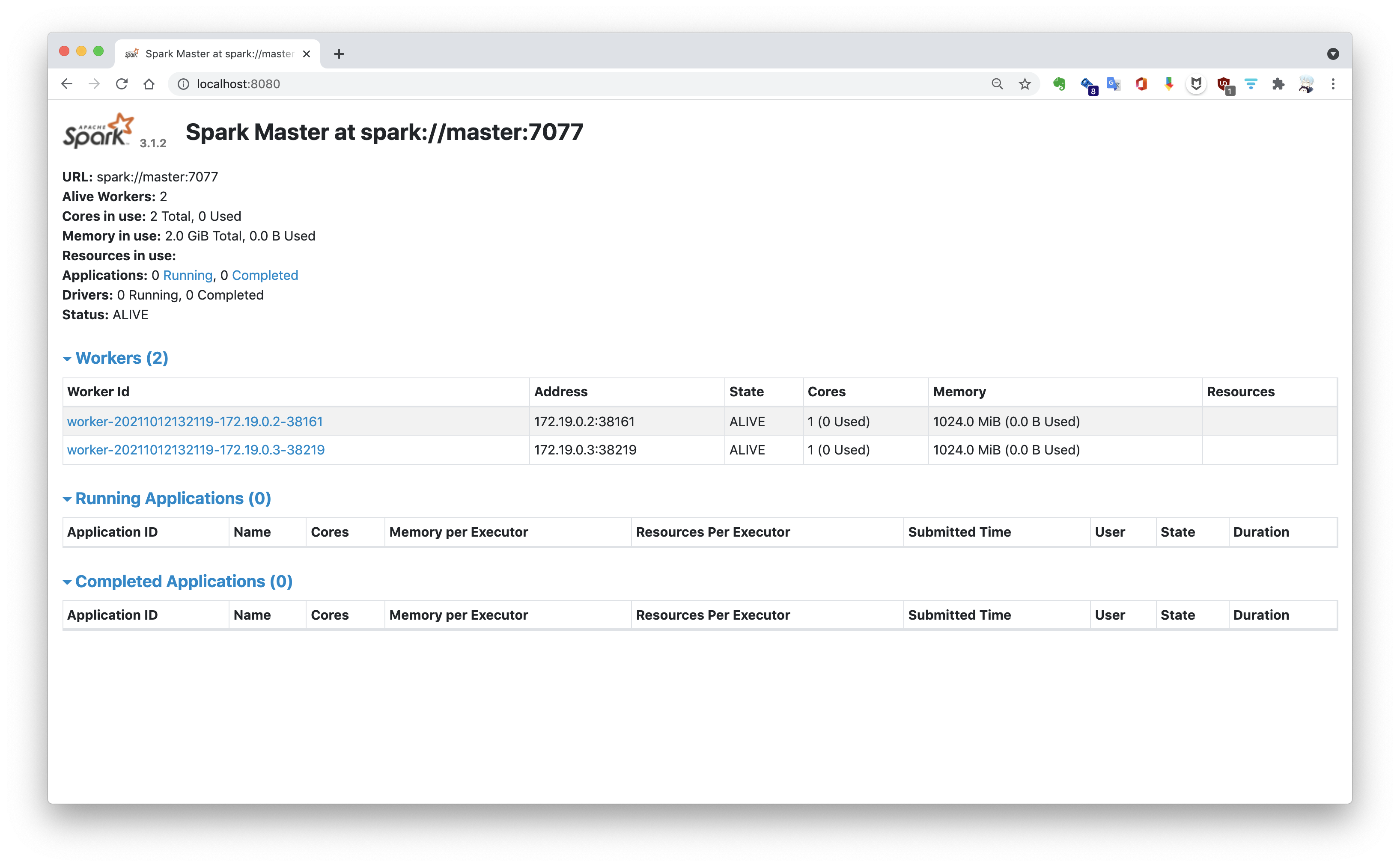
可通过映射的端口访问 Spark Web UI。集群以默认的 Standalone 独立集群模式启动,通过 http://localhost:8080/ 查看集群运行状态:
集群网络 默认情况下,通过 docker-compose 启动的容器集群,会创建并使用名为 镜像名_default 的桥接网络,如 spark_default。集群内的容器处于同一子网网段,因此可以相互通信。
1 2 3 4 5 6 ➜ docker network ls NETWORK ID NAME DRIVER SCOPE 331df1b4ff6d bridge bridge local 3a916c4f1299 host host local 42b893852f97 none null local e425e615144b spark_default bridge local
通过 inspect 命令查看网络配置详情。以下是 spark_default 网络部分配置信息,其使用 172.18.0.0/16 子网网段,并为每个容器实例分配了 IPv4 地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ➜ docker network inspect e4 [ { "Name" : "spark_default" , "Id" : "e425e615144b972265afa9c6e78d7bf22cab446bc5bdece3f188abf5879e8677" , # NETWORK ID "IPAM" : { "Config" : [ { "Subnet" : "172.18.0.0/16" , "Gateway" : "172.18.0.1" } ] }, "Containers" : { "9b9d9c1bb6f873da6b3c72232afab3a451b12cdd4c19d51cc510de1854f95efd" : { # CONTAINER ID "Name" : "spark-spark-worker-1-1" , "IPv4Address" : "172.18.0.2/16" }, "a162bd33dc1936c70259ed2146a1f4a30e52faf66a91624d794336b5357a5f7b" : { "Name" : "spark-spark-worker-2-1" , "IPv4Address" : "172.18.0.4/16" }, "b6ad535e924221e30746722cd486dace692f0f42528eba57347ef4177b355855" : { "Name" : "spark-spark-1" , "IPv4Address" : "172.18.0.3/16" } } } ]
注:同 CONTAINER ID 一样,NETWORK ID 的前两位可以唯一标识一个网络,如 e4。
使用 Spark Shell 进行交互 查看正在运行的容器实例,找到 master 实例的容器 ID:a162bd33dc19。
1 2 3 4 5 ➜ ~ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES a162bd33dc19 s1mplecc/spark-hadoop:3 "/opt/bitnami/script…" 42 hours ago Up About an hour 0.0.0.0:4040->4040/tcp, 0.0.0.0:8080->8080/tcp spark-spark-1 9b9d9c1bb6f8 s1mplecc/spark-hadoop:3 "/opt/bitnami/script…" 42 hours ago Up About an hour 0.0.0.0:8081->8081/tcp spark-spark-worker-1-1 b6ad535e9242 s1mplecc/spark-hadoop:3 "/opt/bitnami/script…" 42 hours ago Up About an hour 0.0.0.0:8082->8081/tcp spark-spark-worker-2-1
执行如下命令进入到 master 容器内部。
1 2 ➜ docker exec -it a1 bash I have no name!@master:/opt/bitnami/spark$
注:实际上 -it 参数的作用是分配一个交互式虚拟终端;容器 ID 的前两位可以唯一标识该容器,如 a1。
现在,可以通过 pyspark 或 spark-shell 命令启动 Spark 交互式命令行,下面以 pyspark 为例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 $ pyspark Python 3.6.15 (default, Sep 24 2021, 11:37:20) [GCC 8.3.0] on linux Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.1.2 /_/ Using Python version 3.6.15 (default, Sep 24 2021 11:37:20) Spark context Web UI available at http://master:4040 Spark context available as 'sc' (master = local[*], app id = local-1633913993830). SparkSession available as 'spark'.
在启动交互式 Shell 时,Spark 驱动器程序(Driver Program)会创建一个名为 sc 的 SparkContext 对象,我们可以通过该对象来创建 RDD 。例如,通过 sc.textFile() 方法读取本地或 HDFS 文件,或者通过 sc.parallelize() 方法直接由 Python 集合创建 RDD。
1 2 3 4 5 6 7 8 9 10 11 12 >>> lines = sc.textFile('README.md' )>>> lines.count()108 >>> lines.filter (lambda line: len (line) > 10 )PythonRDD[3 ] at RDD at PythonRDD.scala:53 >>> lines.filter (lambda line: len (line) > 10 ).count()67 >>> strs = sc.parallelize(['hello world' , 'i am spark' , 'hadoop' ])>>> strs.flatMap(lambda s: s.split(' ' )).collect()['hello' , 'world' , 'i' , 'am' , 'spark' , 'hadoop' ] >>> strs.flatMap(lambda s: s.split(' ' )).reduce(lambda x, y: x + '-' + y)'hello-world-i-am-spark-hadoop'
注:由于 Spark 的惰性求值 特性,只有当执行 Action 操作时,如 count、collect、reduce,才会真正执行计算并返回结果。
Spark Shell 默认以本地模式运行,但也支持以集群模式运行。可以通过指定 --master 参数,如 pyspark --master spark://master:7077,以 Standalone 模式运行 PySpark Shell。
使用 spark-submit 提交独立应用 Spark Shell 支持与存储在硬盘或内存上的分布式数据进行交互,如 HDFS。因此 Spark Shell 适用于即时数据分析,比如数据探索阶段。但我们的最终目的是创建一个独立的 Java、Scala 或 Python 应用,将其提交到 Spark 集群上运行。
Spark 为各种集群管理器提供了统一的工具来提交作业,这个工具就是 spark-submit。
提交 Python 应用 下面以 Python 应用为例,编写 Python 脚本 my_script.py。Python 的 Spark 依赖库就叫做 pyspark,已经包含在 Spark 安装包内,位于 $SPARK_HOME/python 目录下。在独立应用中,我们需要导入该依赖,并且手动创建一个 SparkContext 实例:
1 2 3 4 5 6 7 from pyspark import SparkConf, SparkContextconf = SparkConf().setAppName('My App' ) sc = SparkContext(conf=conf) count = sc.range (1 , 1000 * 1000 * 100 ).filter (lambda x: x > 100 ).count() print ('count: ' , count)
注:SparkConf 用于声明应用配置信息,可以编码在代码中,也可以在命令行以参数形式指定。SparkConf 读取优先级为:代码 > spark-submit 命令行参数 > 以 --properties-file 参数指定的配置文件 > 系统默认配置。
使用 spark-submit 命令提交 Python 脚本,指定 --master 参数提交到集群上。如果未指定该参数,则默认以本地模式运行。
1 2 $ spark-submit --master spark://master:7077 /opt/share/my_script.py count: 99999899
当指定为 spark://host:port 时,应用提交到 Spark 自带的独立集群管理器(Standalone)上运行,默认端口 7077;如果使用 Apache Mesos 集群管理器,需指定为 mesos://host:port,默认端口 5050;使用 Hadoop YARN 则需指定为 yarn。
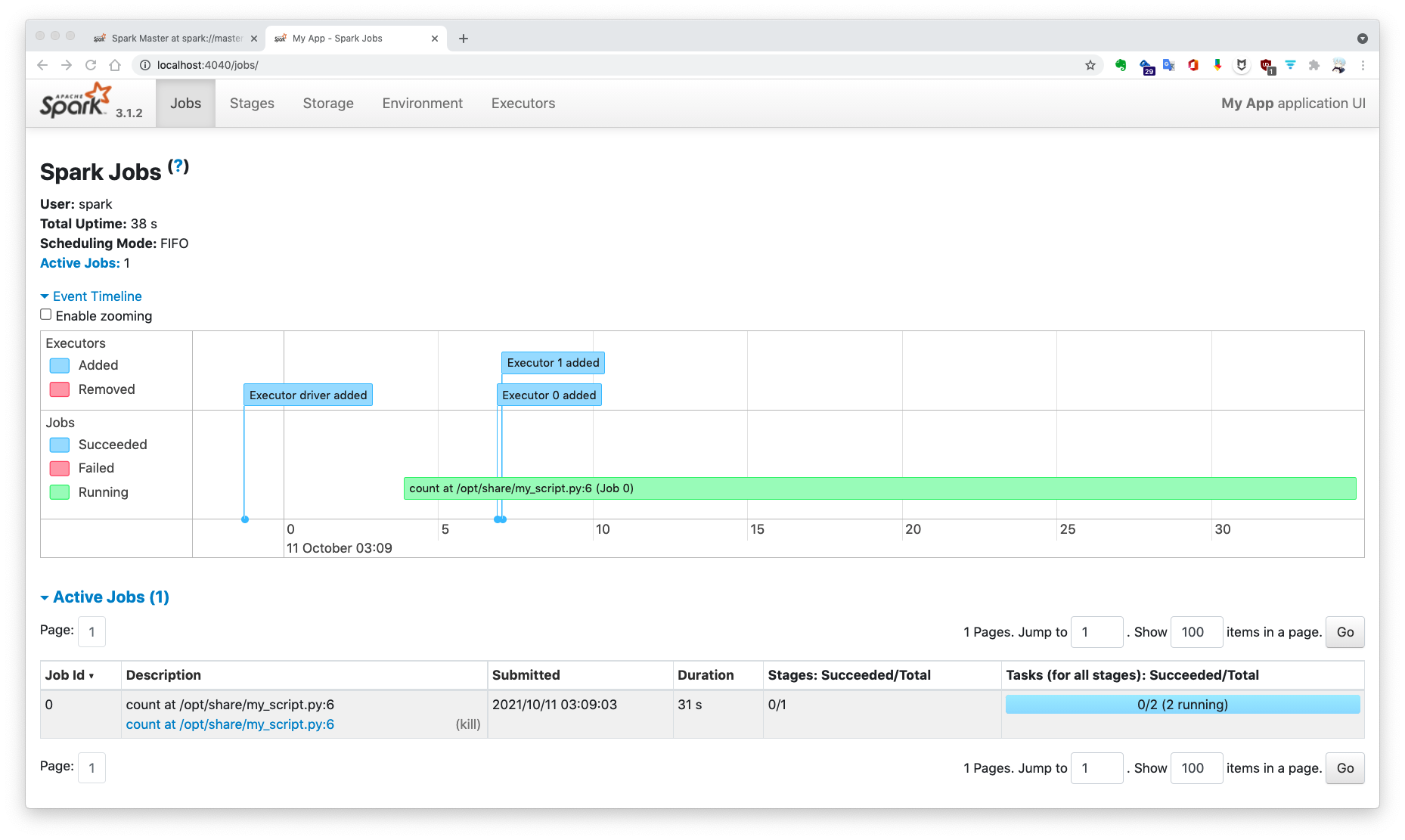
应用运行时,SparkContext 实例会启动应用的 Web UI,默认端口 4040。你可以在此网址查看应用的作业(Job)、组成作业的所有步骤(Stage)、持久化的 RDD 以及执行器状态等信息,这对于应用性能评估有巨大帮助。运行结束后,SparkContext 实例消亡,同时会关闭此 Web UI。
提交 Java 应用 Spark 安装包内置了可以运行的示例 Jar 包,位于 $SPARK_HOME/examples 目录下。向 Spark 集群提交 Jar 包需额外指定程序入口类,即 main 函数所在类。可以通过 jar tf 命令查看 Jar 包所包含的类。
1 2 3 4 5 $ jar tf /opt/bitnami/spark/examples/jars/spark-examples_2.12-3.1.2.jar | grep WordCount org/apache/spark/examples/JavaWordCount.class org/apache/spark/examples/sql/streaming/StructuredKerberizedKafkaWordCount.class org/apache/spark/examples/sql/streaming/StructuredNetworkWordCountWindowed.class ...
找到统计词频的入口类 org.apache.spark.examples.JavaWordCount,以此为例,向 Spark 集群提交 Java 应用。
1 2 3 4 5 6 $ spark-submit --master spark://master:7077 \ --deploy-mode cluster \ --name "JavaWordCount" \ --executor-memory 1g \ --class org.apache.spark.examples.JavaWordCount \ /opt/bitnami/spark/examples/jars/spark-examples_2.12-3.1.2.jar /opt/share/words.txt
注:--deploy-mode 参数决定了驱动器程序的运行位置。默认情况下,即客户端模式(client)下,spark-submit 会在本地(运行该命令的机器上)启动驱动器程序。如果指定为集群模式(cluster),驱动器程序将会运行在随机选取的一个工作节点上,此时即使 ctrl-c 中断 spark-submit 命令,也不会影响应用继续运行。因此,集群模式适用于需要长时间作业的应用。此外,Spark Standalone 目前不支持以集群模式运行 Python 应用(可以使用 YARN 集群来解决)。
Spark 3.1.2 官方文档 : Currently, the standalone mode does not support cluster mode for Python applications.
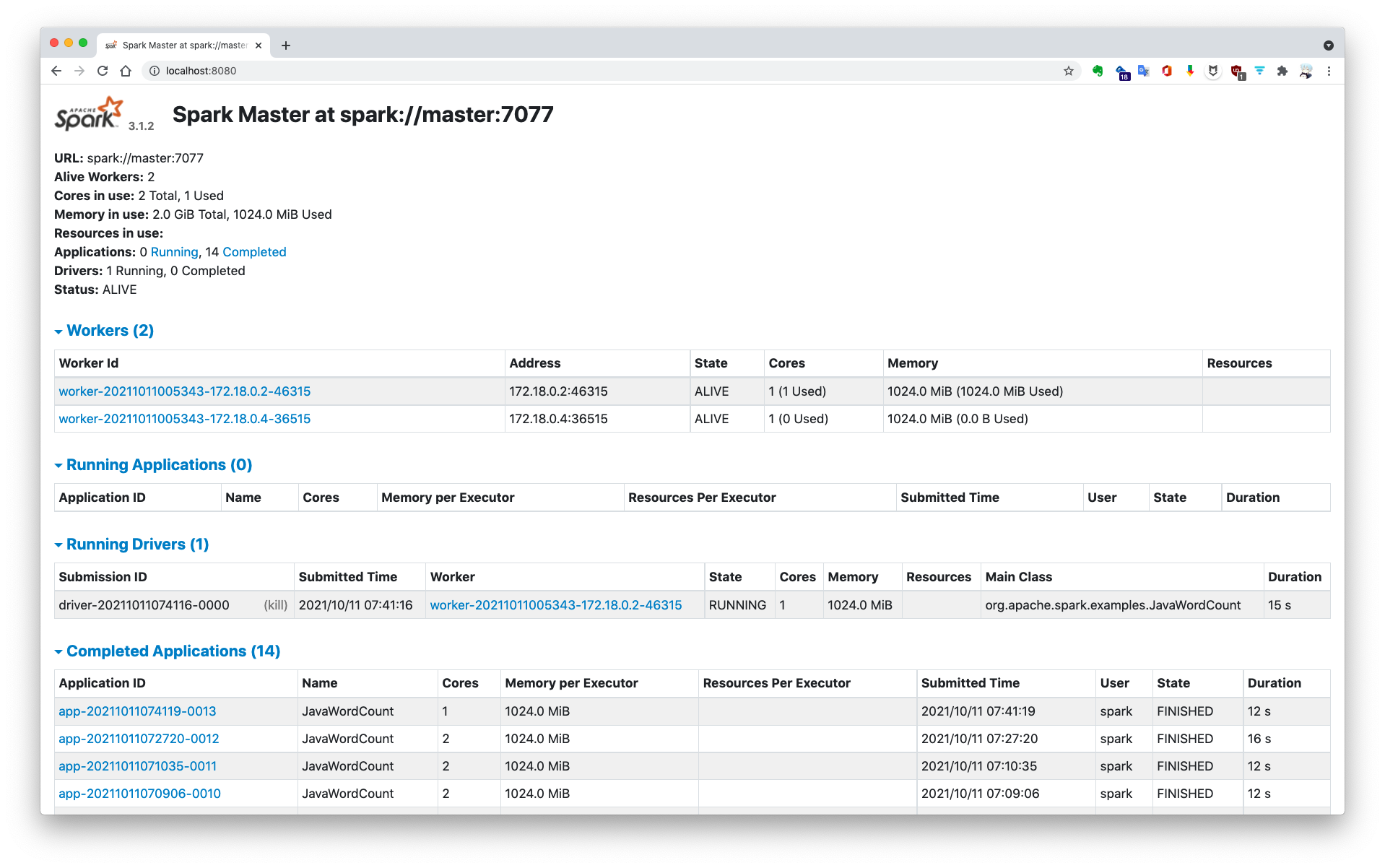
当通过集群模式运行上述命令时,驱动器程序 Driver 并不是运行主节点上,而是运行在 IP 为 172.18.0.2 的工作节点上:
安装 Hadoop Hadoop 由分布式文件系统 HDFS、分布式计算框架 MapReduce 和资源管理框架 YARN 组成。MapReduce 是面向磁盘的,运行效率受到磁盘读写性能的约束,Spark 延续了 MapReduce 编程模型的设计思路,提出了面向内存的分布式计算框架,性能较之 MapReduce 有了 10~100 倍的提升。与此同时,Spark 框架还对 HDFS 做了很好的支持,并支持运行在 YARN 集群上。
Spark uses Hadoop’s client libraries for HDFS and YARN. Downloads are pre-packaged for a handful of popular Hadoop versions.
由于 Spark 使用了 Hadoop 的客户端依赖库,所以 Spark 安装包会指定依赖的 Hadoop 特定版本,如 spark-3.1.2-bin-hadoop3.2.tgz。而 bitnami/spark 镜像中只包含 Hadoop 客户端,并不包含服务器端。因此,如果需要使用 HDFS 和 YARN 功能,还需要部署 Hadoop 集群。
将 Hadoop 部署在 Spark 集群上,可以避免不必要的网络通信,并且面向磁盘的 HDFS 与面向内存的 Spark 天生互补。因此,考虑在 bitnami/spark 镜像基础上构建安装有 Hadoop 的新镜像。
确定 Hadoop 版本 首先,需要确定 bitnami/spark 镜像所依赖的 Hadoop 版本。启动 pyspark 进行查看:
1 2 3 $ pyspark >>> sc._gateway.jvm.org.apache.hadoop.util.VersionInfo.getVersion()'3.2.0'
在 Hadoop 官网找到 Hadoop 3.2.0 安装包的下载地址 ,稍后在构建镜像时通过 curl -OL 命令下载此安装包。
准备配置文件及启动脚本 在工作目录下创建 config 文件夹,编写需要覆盖的 Hadoop 配置文件。完整的配置文件已经上传至 GitHub:s1mplecc/spark-hadoop-docker 。
1 2 3 4 5 6 7 8 ➜ tree ~/docker/spark/config config ├── core-site.xml ├── hadoop-env.sh ├── hdfs-site.xml ├── mapred-site.xml ├── workers └── yarn-site.xml
注:其他详细配置请参考 Apache Hadoop 官方文档:Hadoop Cluster Setup 。
除了配置文件外,还需要编写 Hadoop 启动脚本。由于设置了 ssh 免密通信,首先需要启动 ssh 服务,然后依次启动 HDFS 和 YARN 集群。
1 2 3 4 #!/bin/bash service ssh start $HADOOP_HOME /sbin/start-dfs.sh$HADOOP_HOME /sbin/start-yarn.sh
基于 bitnami/spark 构建新镜像 在工作目录下,创建用于构建新镜像的 Dockerfile。新镜像基于 docker.io/bitnami/spark:3,依次执行如下指令:
设置 Hadoop 环境变量;
配置集群间 ssh 免密通信。此处直接将 ssh-keygen 工具生成的公钥写入 authorized_keys 文件中,由于容器集群基于同一个镜像创建的,因此集群的公钥都相同且 authorized_keys 为自己本身;
下载 Hadoop 3.2.0 安装包并解压;
创建 HDFS NameNode 和 DataNode 工作目录;
覆盖 $HADOOP_CONF_DIR 目录下的 Hadoop 配置文件;
拷贝 Hadoop 启动脚本并设置为可执行文件;
格式化 HDFS 文件系统;
在入口脚本中启动 ssh 服务。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 FROM docker.io/bitnami/spark:3 LABEL maintainer="s1mplecc <s1mple951205@gmail.com>" LABEL description="Docker image with Spark (3.1.2) and Hadoop (3.2.0), based on bitnami/spark:3. \ For more information, please visit https://github.com/s1mplecc/spark-hadoop-docker." USER rootENV HADOOP_HOME="/opt/hadoop" ENV HADOOP_CONF_DIR="$HADOOP_HOME/etc/hadoop" ENV HADOOP_LOG_DIR="/var/log/hadoop" ENV PATH="$HADOOP_HOME/hadoop/sbin:$HADOOP_HOME/bin:$PATH" WORKDIR /opt RUN apt-get update && apt-get install -y openssh-server RUN ssh-keygen -t rsa -f /root/.ssh/id_rsa -P '' && \ cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys RUN curl -OL https://archive.apache.org/dist/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz RUN tar -xzvf hadoop-3.2.0.tar.gz && \ mv hadoop-3.2.0 hadoop && \ rm -rf hadoop-3.2.0.tar.gz && \ mkdir /var/log /hadoop RUN mkdir -p /root/hdfs/namenode && \ mkdir -p /root/hdfs/datanode COPY config/* /tmp/ RUN mv /tmp/ssh_config /root/.ssh/config && \ mv /tmp/hadoop-env.sh $HADOOP_CONF_DIR /hadoop-env.sh && \ mv /tmp/hdfs-site.xml $HADOOP_CONF_DIR /hdfs-site.xml && \ mv /tmp/core-site.xml $HADOOP_CONF_DIR/core-site.xml && \ mv /tmp/mapred-site.xml $HADOOP_CONF_DIR/mapred-site.xml && \ mv /tmp/yarn-site.xml $HADOOP_CONF_DIR/yarn-site.xml && \ mv /tmp/workers $HADOOP_CONF_DIR/workers COPY start-hadoop.sh /opt/start-hadoop.sh RUN chmod +x /opt/start-hadoop.sh && \ chmod +x $HADOOP_HOME /sbin/start-dfs.sh && \ chmod +x $HADOOP_HOME /sbin/start-yarn.sh RUN hdfs namenode -format RUN sed -i "1 a /etc/init.d/ssh start > /dev/null &" /opt/bitnami/scripts/spark/entrypoint.sh ENTRYPOINT [ "/opt/bitnami/scripts/spark/entrypoint.sh" ] CMD [ "/opt/bitnami/scripts/spark/run.sh" ]
在工作目录下,执行如下命令构建镜像:
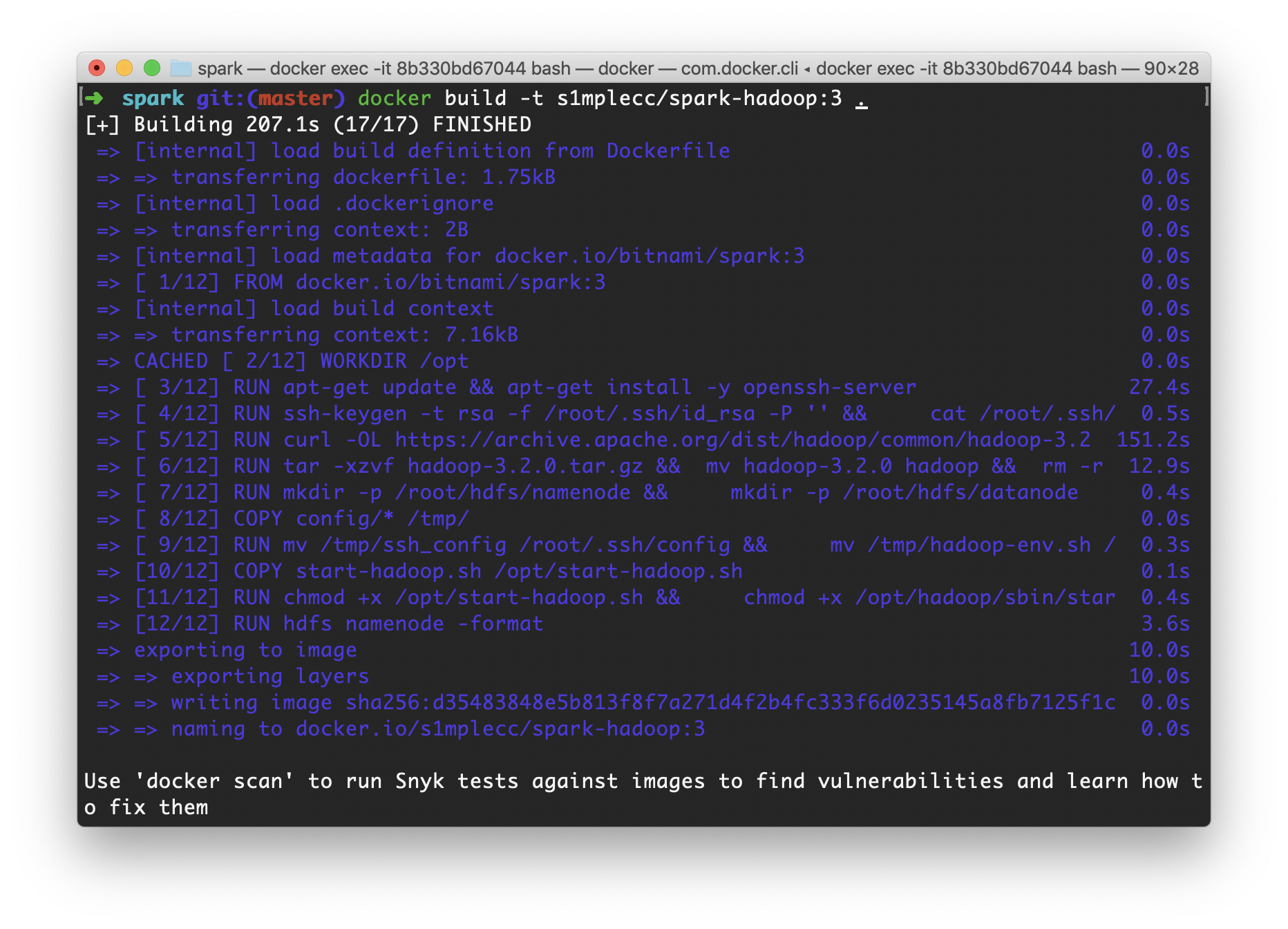
1 ➜ docker build -t s1mplecc/spark-hadoop:3 .
构建过程将按照 Dockerfile 中的指令依次进行。
启动 spark-hadoop 集群 构建镜像完成后,还需要修改 docker-compose.yml 文件,使其从新的镜像 s1mplecc/spark-hadoop:3 中启动容器集群,同时映射 Hadoop Web UI 端口。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 version: '2' services: spark: image: s1mplecc/spark-hadoop:3 hostname: master environment: - SPARK_MODE=master - SPARK_RPC_AUTHENTICATION_ENABLED=no - SPARK_RPC_ENCRYPTION_ENABLED=no - SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no - SPARK_SSL_ENABLED=no volumes: - ~/docker/spark/share:/opt/share ports: - '8080:8080' - '4040:4040' - '8088:8088' - '8042:8042' - '9870:9870' - '19888:19888' spark-worker-1: image: s1mplecc/spark-hadoop:3 hostname: worker1 environment: - SPARK_MODE=worker - SPARK_MASTER_URL=spark://master:7077 - SPARK_WORKER_MEMORY=1G - SPARK_WORKER_CORES=1 - SPARK_RPC_AUTHENTICATION_ENABLED=no - SPARK_RPC_ENCRYPTION_ENABLED=no - SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no - SPARK_SSL_ENABLED=no volumes: - ~/docker/spark/share:/opt/share ports: - '8081:8081' spark-worker-2: image: s1mplecc/spark-hadoop:3 hostname: worker2 environment: - SPARK_MODE=worker - SPARK_MASTER_URL=spark://master:7077 - SPARK_WORKER_MEMORY=1G - SPARK_WORKER_CORES=1 - SPARK_RPC_AUTHENTICATION_ENABLED=no - SPARK_RPC_ENCRYPTION_ENABLED=no - SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no - SPARK_SSL_ENABLED=no volumes: - ~/docker/spark/share:/opt/share ports: - '8082:8081'
运行 docker-compose 启动命令重建集群,不需要停止或删除旧集群。
1 2 3 4 5 ➜ docker-compose up -d [+] Running 0/3 ⠼ Container spark-spark-1 Recreate 6.4s ⠼ Container spark-spark-worker-2-1 Recreate 6.4s ⠼ Container spark-spark-worker-1-1 Recreate 6.4s
启动容器集群后,进入 master 容器执行启动脚本:
1 2 3 4 5 6 7 ➜ docker exec -it a1 bash $ ./start-hadoop.sh Starting OpenBSD Secure Shell server: sshd. Starting namenodes on [master] Starting secondary namenodes [master] Starting resourcemanager Starting nodemanagers
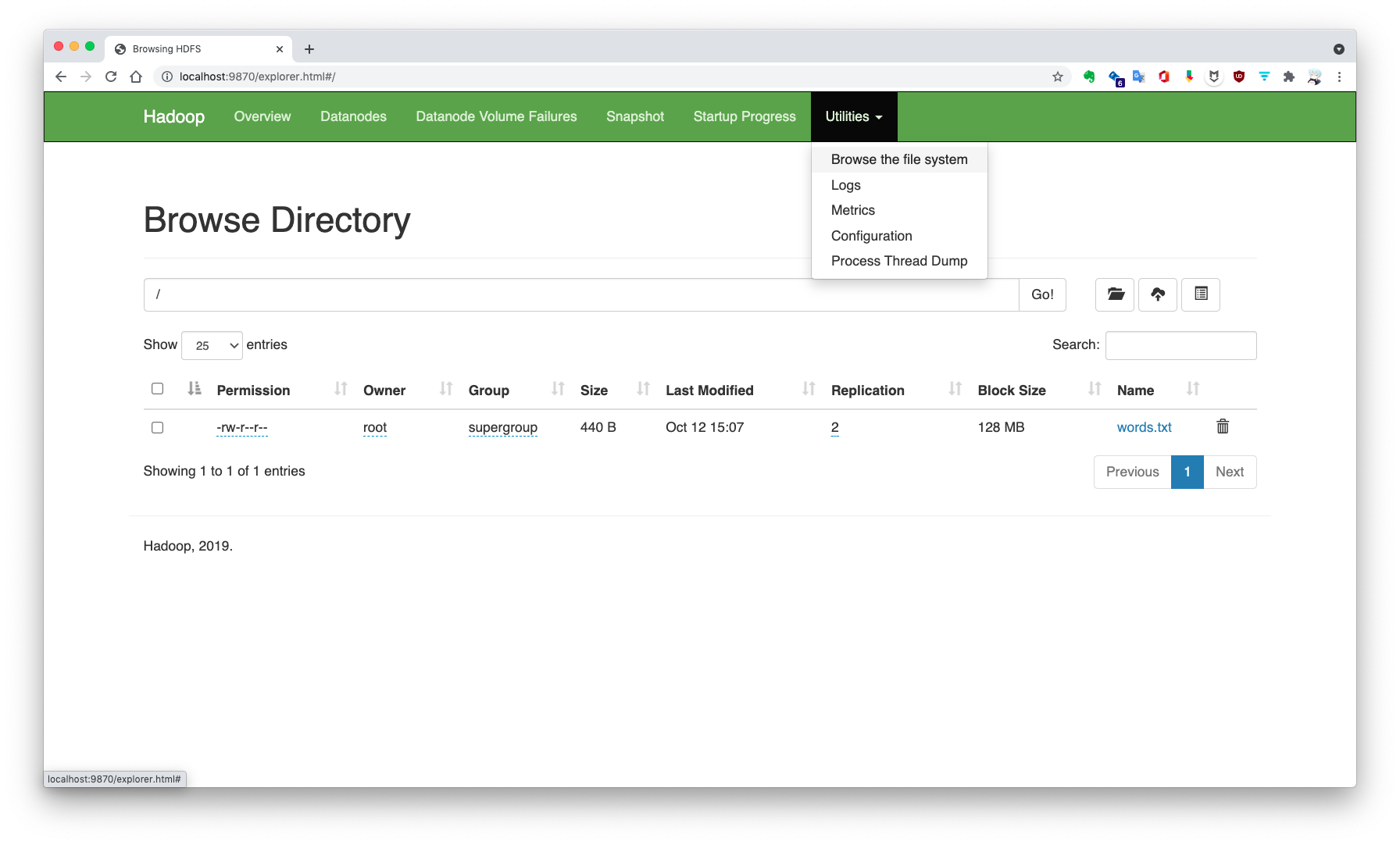
向 HDFS 写入文件 使用命令将共享文件中的 words.txt 写入 HDFS:
1 2 3 4 $ hadoop fs -put /opt/share/words.txt / $ hdfs dfs -ls / Found 1 items -rw-r--r-- 2 root supergroup 440 2021-10-12 07:07 /words.txt
写入的文件可以在 HDFS Web UI 上进行浏览:
Spark 访问 HDFS 现在,可以通过 Spark 访问 HDFS 了,访问 URI 为 hdfs://master:9000,这是配置在 core-site.xml 文件中的默认文件系统 fs.defaultFS。下面通过 PySpark 演示如何读取和存储 HDFS 上的数据。
1 2 3 4 5 6 $ pyspark >>> lines = sc.textFile('hdfs://master:9000/words.txt' )>>> lines.collect()['Apache Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for incremental computation and stream processing.' ] >>> words = lines.flatMap(lambda x: x.split(' ' ))>>> words.saveAsTextFile('hdfs://master:9000/split-words.txt' )
HDFS 上的文件被读取为 RDD,在内存上进行 Transformation 后写入 HDFS。写入的文件被存储到 HDFS 的 DataNode 块分区上。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 $ hdfs dfs -ls / Found 2 items drwxr-xr-x - root supergroup 0 2021-10-12 13:28 /split-words.txt -rw-r--r-- 2 root supergroup 440 2021-10-12 13:24 /words.txt $ hdfs dfs -ls /split-words.txt Found 3 items -rw-r--r-- 2 root supergroup 0 2021-10-12 13:28 /split-words.txt/_SUCCESS -rw-r--r-- 2 root supergroup 441 2021-10-12 13:28 /split-words.txt/part-00000 -rw-r--r-- 2 root supergroup 0 2021-10-12 13:28 /split-words.txt/part-00001 $ hdfs dfs -cat /split-words.txt/part-00000 Apache Spark is ...
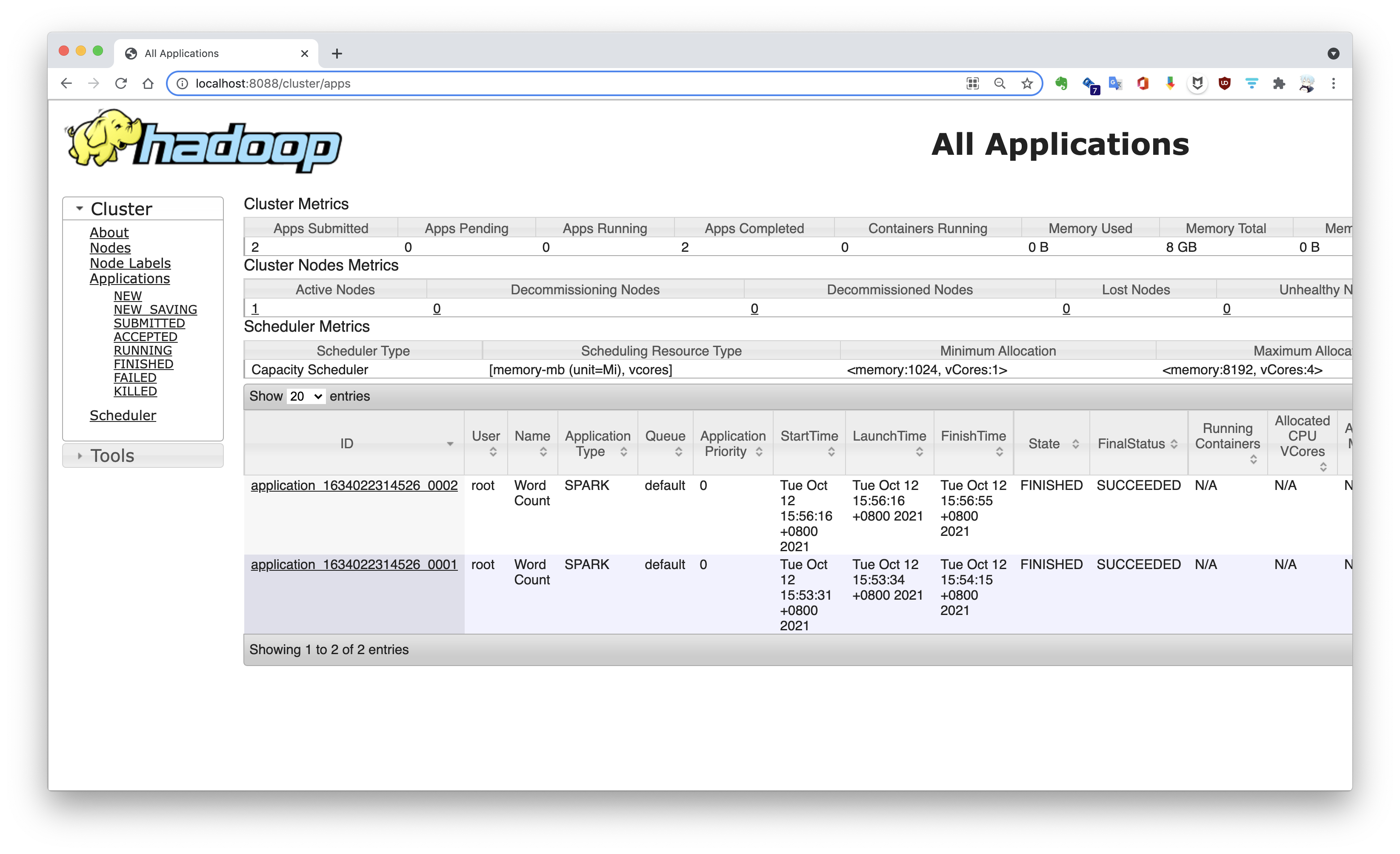
将 Spark 应用提交到 YARN 集群 在运行 Hadoop 启动脚本时同时启动了 HDFS 和 YARN,现在可以将 Spark 应用提交到 YARN 集群上。默认使用 HDFS 文件系统,如需读取本地文件,还需要指定 file:// 前缀。
1 2 3 4 5 6 $ spark-submit --master yarn \ --deploy-mode cluster \ --name "Word Count" \ --executor-memory 1g \ --class org.apache.spark.examples.JavaWordCount \ /opt/bitnami/spark/examples/jars/spark-examples_2.12-3.1.2.jar /words.txt
提交到 YARN 上的应用通过 ResourceManager Web UI 进行查看,默认端口 8088。
Web UI 汇总
注:星号标注的为较常用的 Web UI。
参考