初赛题目
主办方提供了 black/white/test 三个 pcap 文件夹,其中 black 和 white 分别是检测出有/无恶意软件感染的客户端 IP 组,要求选手对 test 数据集进行判定。

解题思路
该题的解题过程应分为以下三个大步骤:
- 特征选择(Feature Selection),选取对于区分正常/恶意流量有明显作用的 Features。
- 特征提取(Feature Extraction),从 pcap 文件中提取上述 Features,并转换为模型训练所需要的格式。我们选择的特征提取工具为 Zeek。
- 模型训练(Model Training),选择合适的机器学习模型对三类 pcap 文件进行训练和预测。我们选择的 Python 机器学习库为 scikit-learn。
解题步骤
合并pcap文件
主办方提供的 pcap 文件,其中 white/black 各有 1500 个 pcap,test 2000 个 pcap
1 | ➜ tree eta_1 |
使用 mergecap 命令将 pcap 文件合并为三个大的 pcap 文件
1 | ➜ mergecap -w black.pcap ./eta_1/black/*.pcap |
特征选择
参考了多篇加密恶意流量检测的研究论文,我们初步确定了以下四类需要提取的 Features,包括TLS客户端指纹信息、数据包元数据、HTTP头部信息和DNS响应信息。
TLS client fingerprinting:
在进行TLS握手时,会进行如下几个步骤:
- Client Hello,客户端提供支持的加密套件数组(cipher suites);
- Server Hello,由服务器端选择一个加密套件,传回服务器端公钥,并进行认证和签名授权(Certificate + Signature);
- 客户端传回客户端公钥(Client Key Exchange),客户端确立连接;
- 服务器端确立连接,开始 HTTP 通信。
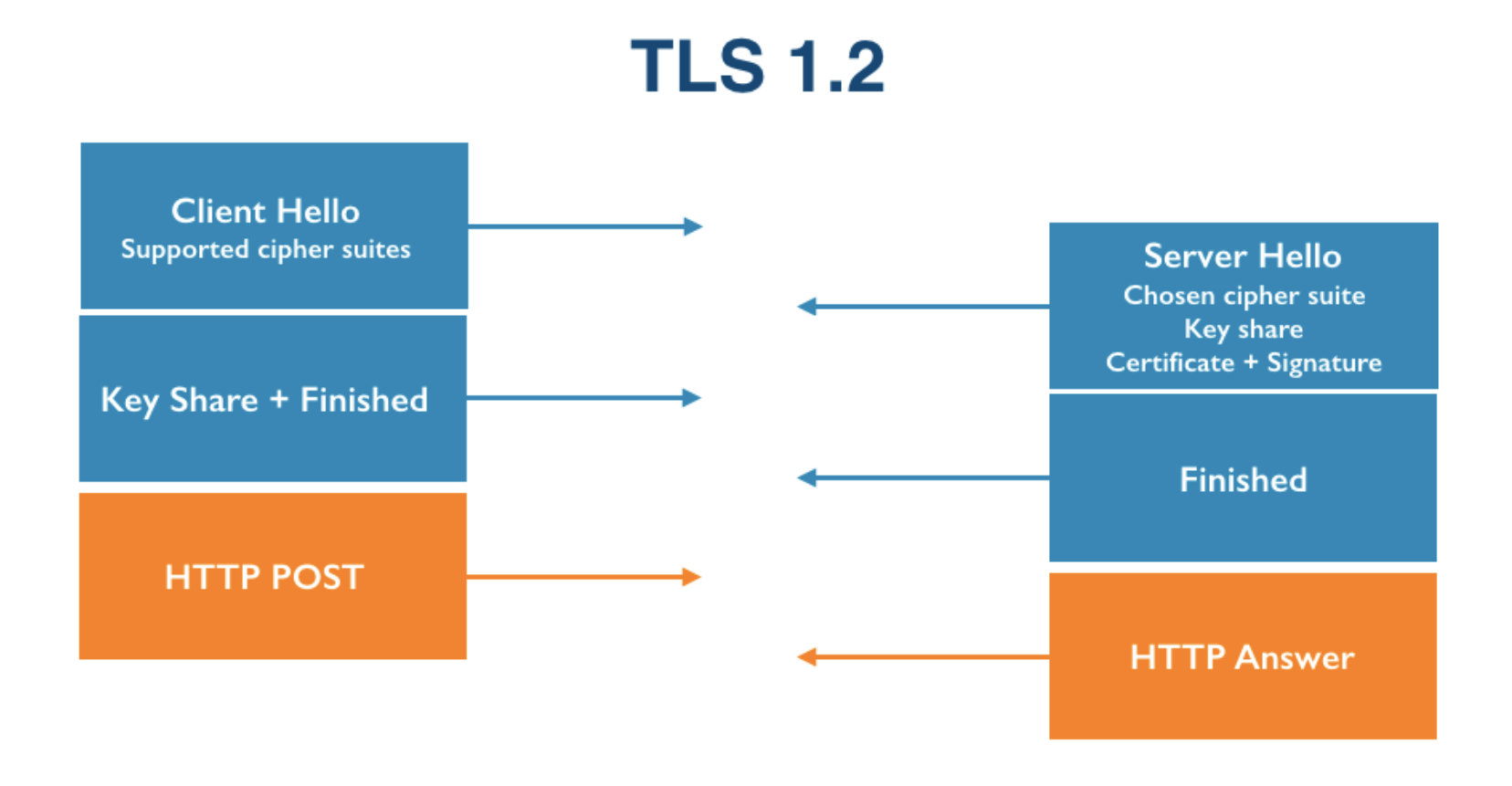
以上加粗的四种消息类型可以通过 TLS 握手协议的 Handshake Type 做区分:
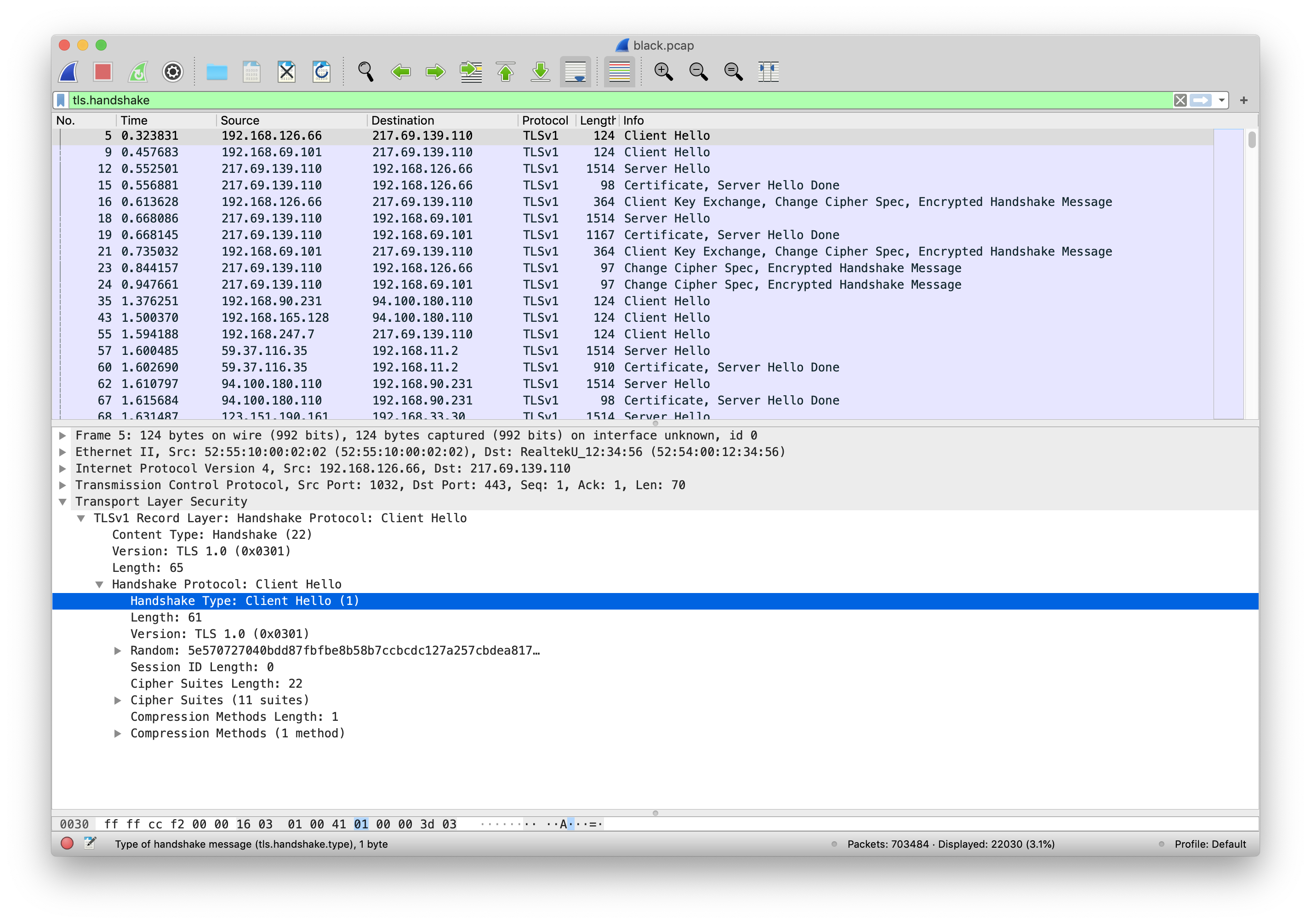
基于此,我们选取了以下特征:
- 客户端支持的加密套件数组(Cipher suites),服务器端选择的加密套件。
- 支持的扩展(TLS extensions),若分别用向量表示客户端提供的密码套件列表和 TLS 扩展列表,可以从服务器发送的确认包中的信息确定两组向量的值。
- 客户端公钥长度(Client public key length),从密钥交换的数据包中,得到密钥的长度。
- Client version,the preferred TLS version for the client
- 是否非CA自签名,统计数据表示,恶意流量约70%出现非CA认证服务器且自签名的情况,非恶意流量约占0.1%。此项判断的依据是:未出现
CA: True字段(默认非 CA 机构)且signedCertificate中的issuer字段等于subject字段。
数据包元数据:
- 数据包的大小,数据包的长度受 UDP、TCP 或者 ICMP 协议中数据包的有效载荷大小影响,如果数据包不属于以上协议,则被设置为 IP 数据包的大小。
- 到达时间序列
- 字节分布
HTTP头部信息:
- Content-Type,正常流量 HTTP 头部信息汇总值多为
image/*,而恶意流量为text/*、text/html、charset=UTF-8或者text/html;charset=UTF-8。 - User-Agent
- Accept-Language
- Server
- HTTP响应码
DNS响应信息:
- 域名的长度:正常流量的域名长度分布为均值为6或7的高斯分布(正态分布);而恶意流量的域名(FQDN全称域名)长度多为6(10)。
- 数字字符及非字母数字(non-alphanumeric character)的字符占比:正常流量的DNS响应中全称域名的数字字符的占比和非字母数字字符的占比要大。
- DNS解析出的IP数量:大多数恶意流量和正常流量只返回一个IP地址;其它情况,大部分正常流量返回2-8个IP地址,恶意流量返回4或者11个IP地址。
- TTL值:正常流量的TTL值一般为60、300、20、30;而恶意流量多为300,大约22%的DNS响应汇总TTL为100,而这在正常流量中很罕见。
- 域名是否收录在Alexa网站:恶意流量域名信息很少收录在Alexa top-1,000,000中,而正常流量域名多收录在其中。
特征提取
特征提取我们采用的工具是 Zeek,它的前身是 Bro,一款网络安全监视(Network Security Monitoring)工具,它定义了自己的 DSL 语言,支持直接处理 pcap 文件生成各类日志文件,包括 dns、http、smtp 等:
1 | ➜ ls |
Zeek 网上有一些现成的脚本,我们采用的是 Zeek FlowMeter,它基于 OSI 七层协议的网络层和传输层,可以分析并生成一些 Packets 到达时间序列、Packet 字节大小和元数据等新特征。
在使用时,我们需要在 local.zeek 配置文件中加入 @load flowmeter,这样 Zeek 在执行时会加载 flowmeter.zeek 并生成对应的 flowmeter.log,下面列出了 FlowMeter 提取出的一些特征,包括上下行包总数、包负载均值方差等。其他详细的特征请见 zeek-flowmeter GitHub官方文档。
| Feature Name | Description | exists in FlowMeter |
|---|---|---|
| uid | The ID of the flow as given by Zeek | No |
| flow_duration | The length of the flow in seconds (maximal precision ms). If only on packet was seen the duration is 0. | Yes |
| fwd_pkts_tot | The number of packets travelling in the forward direction. | Yes |
| bwd_pkts_tot | The number of packets travelling in the backwards direction. | Yes |
| fwd_pkts_per_sec | The average number of forward packets transmitted per second during the flow. If the duration is 0 then this feature is also set to 0. | Yes |
| fwd_pkts_payload.avg | The average payload size, in bytes, seen in the forward direction. | Yes |
| fwd_pkts_payload.std | The standard deviation of the payload size, in bytes, seen in the forward direction. | Yes |
| … | … | … |
除 flowmeter.log 之外我们还需要关注 conn.log、ssl.log 和 X509.log。这几个日志共同字段 uid 是 Zeek 根据一次连接的源/目的 IP、源/目的端口四元组生成的唯一 ID。为了方便后续的处理,我们将这几个日志文件统一读入,使用 uid 字段连接后转成 csv 格式输出到文件。最终我们提取的特征如下:

特征向量化
因为模型训练不支持 str 类型的特征,所以需要对 version 和 server_cipher 等字段进行特征向量化。
| version | cipher |
|---|---|
| TLSv10 | TLS_RSA_WITH_3DES_EDE_CBC_SHA |
| TLSv10 | TLS_RSA_WITH_3DES_EDE_CBC_SHA |
| TLSv12 | TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 |
| TLSv10 | TLS_RSA_WITH_RC4_128_MD5 |
| … | … |
DictVectorizer 是 scikit-learn 库中用于将 Python dict 对象表示的特征数组转换为 scikit-learn Estimator 使用的 NumPy/SciPy 表示形式。
1 | def convert_by_dict(src_file, dest_file): |
向量化后的效果:
| version=SSLv3 | version=TLSv10 | version=TLSv12 | version=TLSv11 | cipher=TLS_RSA_WITH_3DES_EDE_CBC_SHA | … |
|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 | … |
| 0 | 1 | 0 | 0 | 0 | … |
| 0 | 1 | 0 | 0 | 0 | … |
| 0 | 0 | 1 | 0 | 0 | … |
| … | … | … | … | … | … |
另外需要注意的是,需要对特征列进行补全,否则在进行模型训练时会出现特征个数不匹配的问题。例如:white.pcap 文件中 TLS versions 包含 ['TLSv1.0', 'TLSv1.2', 'SSLv3'] 三个版本,而 black 和 test 的 pcap 文件中除这三个版本外还包含 'TLSv1.1' 版本,所以需要在 white 中加入 version=TLSv1.1 全为 0 的列。
模型选取及参数
需要注意的是:white 已明确没有被恶意软件感染,所以产生的流量可以全部标注为正常流量,而 black 明确的只是客户端感染了恶意软件,但产生的流量不一定全为恶意流量。所以实际上是对不平衡样本数据进行训练和预测。遵循这个思路,可以采用 Anomaly Detector + Misuse Detector 的联合分类器进行训练。

基于全正常流量的 white.pcap 文件进行 one-class classification 训练异常检测器 Anomaly Detector;再用该分类器对 black.pcap 文件进行推理预测恶意流量;结合 black 中检测的恶意流量和 white 正常流量训练二分类器;最终采用二分类器对 test 中的流量进行检测。
数据处理
数据集是我们之前经过 Zeek 特征提取、特征向量化后产生的 white.csv、black.csv 和 test.csv 三个 csv 文件,使用 pandas 读入后定义一个列名数组 data_f 来获取相应特征:
1 | white_df = pd.read_csv("white.csv",index_col=0) |
将 white_flow 和 black_flow 两个数据集合并做归一化处理,得到total_data:
1 | merge_flow = white_flow.append(black_flow, ignore_index=True) |
然后我们从 total_data 中提取 white 的训练集和测试集,同时需要提取 black 的测试集:
1 | # white 训练集和测试集(标签1表示正常流量) |
Anomaly Detector
在 black 数据集中同时存在恶意流量和正常流量,没有明确的标注,无法直接用于训练分类器。而 white 数据集中都是正常流量,可以先用 white 数据集来训练一个 Anomaly Detector 分类器。然后用这个分类器在 black 数据集中推理得到哪些是恶意流量。我们的模型选取的隔离森林 IsolationForest。
1 | clf = IsolationForest(max_samples=len(x_train), contamination=0.3) |
训练误用检测器 Misuse Detector
假设这些由异常检测器识别的可疑流量是恶意流量,我们就有了恶意流量的标注。接下来我们用这些恶意流量 labels,结合 white 数据集中的正常流量 labels,来训练一个 Misuse Detector。我们选取了 XGBoost 基于树的模型,目标选取为多分类问题(分类数为2):
1 | # XGbooster Model gbtree multi:softmax 2 |
下一步对于数据做 Max/Min 归一化,然后分割出训练集、验证集、测试集:
1 | # Max/Min 归一化 |
进行 XGBoost 模型训练:
1 | def evalerror(preds, dtrain): |
用模型去预测结果:
1 | # test 数据集上使用模型进行预测 |
总结与反思
这次比赛几次提交点的最好成绩是 72.5 分,距离复赛要求的名次差几名,很遗憾无缘复赛。总结了失利的几点原因:
- 对恶意流量的特征不熟悉,导致花了很多时间去确定需要提取哪些 Features,浪费了前面的检查点。其实我们最后提取的 Features 还有很大的提升空间,比如数据包的时间序列特征,我们只提取了均值、方差等特征,还有字节分布等重要特征未进行有效提取。
![e67c9834b783a0c2b314e2dd35719671.png]()
- 对模型的选择和参数认识不够,只是盲目的更换模型和调参,一开始发现模型和参数对结果的影响很大,实际上还是特征提取的不够好。当提取了能有效区分正常/恶意流量的特征后,模型的选择和参数对结果影响就较小了,所以最重要的依然是有效特征的提取。
参考
- Shekhawat, A. S. (2018). Analysis of Encrypted Malicious Traffic.
- Jenseg, O. (2019). A machine learning approach to detecting malware in TLS traffic using resilient network features (Master’s thesis, NTNU).
- Shekhawat, A. S., Di Troia, F., & Stamp, M. (2019). Feature analysis of encrypted malicious traffic. Expert Systems with Applications, 125, 130-141.
- Analysing PCAPs with Bro/Zeek
- Machine Learning Applications in Misuse and Anomaly Detection
- imbalanced-classification-with-python
- scikit-learn GitHub doc: Feature extraction
- 基于机器学习的TLS恶意加密流量检测方案
- 利用背景流量数据(contexual flow data)识别TLS加密恶意流量
